

ATARI vs Gitlab - część 1
Data publikacji:28.03.2020
A na co mnie ten cały Git?
No w zasadzie to nie jest wcale niezbędny. I tutaj mógłbym zakończyć ten niepotrzebny artykuł i podziękować za uwagę, ale jednak... Pomimo, że można sobie doskonale bez niego radzić, to warto spóbować. Z kilku powodów:
- jest wygodnie mieć dostęp do swojego kodu z dowolnego miejsca i dowolnego komputera podłączonego do sieci,
- jeżeli pracujemy nad tym samym projektem z kilku maszyn, to odpada nam problem, gdzie mamy najnowszy kod, i czy sobie czegoś przypadkiem nie nadpiszemy,
- super wygoda przy pracy grupowej nad jednym projektem,
- można prześledzić zmiany od dowolnego momentu w czasie i przywrócić jak sobie coś popsujemy,
A jeżeli skorzystamy do tego ze zdalnego i darmowego hostingu naszego projektu, takiego jak GitLab, GitHub czy BitBucket, to dostajemy w zamian jeszcze inne dodatkowe korzyści:

- możemy edytować nasze pliki nawet w przegladarce,
- mamy wygodne narzędzie do śledzenia zmian w plikach,
- wbudowany system zgłaszania błędów,
- możliwość konfiguracji systemu ciągłej integracji, aby po kazdej zmianie serwis sam automatycznie kompilował nasz projekt i publikował najnowszą wersję!
Wynika z tego, że w zasadzie możemy sobie programować nawet z telefonu, a system sam zbuduje nam wynikowe pliki. Nie potrzebujemy mieć zainstalowanego żadnego kompilatora!!!
Czy to nie jest wystarczający argument, żeby spróbować?
No to w końcu Git czy GitLab?
Oba! Zaraz wytłumaczę na czym polega różnica i dlaczego potrzebujemy obydwu. Wszędzie gdzie będę mówił o GitLabie, równie dobrze możemy wstawić sobie każdy inny serwis hostingowy oparty o Gita. Pomimo tego, że GitHub jest chyba nieco popularniejszy, ja do swoich atarowskich projektów wybrałem GitLaba. W czasie gdy porównywałem ich możliwości GitLab oferował nieogarniczoną ilość prywatnych repozytoriów co zadecydowało. Teraz chyba już GitHub też nie ma limitu w darmowej opcji, ale GitLab sprawdza mi się doskonale i nic mu nie brakuje, więc tak już zostało. Wydaje mi się, że wiekszość rzeczy o których będę tutaj pisał działa podobnie, więc jak juz wybrałeś inny hosting, to nie ma co panikować, powinno zadziałać.
Ale zacznijmy od samego Gita. Git to bardzo wygodny, nowoczesny i rozproszony system kontroli wersji. Co to w ogóle oznacza? Systemami kontroli wersji nazywamy narzędzia, które pozwalają nam na śledzenie zmian w kodzie źródłowym, wersjonowanie, przechowywanie i synchronizację źródeł na zdalnych serwerach, oraz ułatwiają pracę grupową nad plikami i łączenie zmian dokonanych przez kilka osób w tym samym czasie. Ja zazwyczaj nad retro projektami pracuję sam, więc korzystam zazwyczaj tylko z tych pierwszych udogodnień.
Systemów kontroli wersji jest i było wiele. Zmieniały sie one na przestrzeni lat wraz z rozwojem technologii, ale od paru dobrych lat Git ze względu na swoje unikalne cechy jest liderem, i obawiam się, że jeszcze jakiś czas tak pozostanie.
Git jest typem systemu rozproszonego, co oznacza, że każdy użytkownik wspólnego projektu ma u siebie pełną kopię całego repozytorium plików, którą synchronizuje z innymi użytkownikami i/lub innymi komputerami. I naszym wspólnym punktem synchronizacji będzie właśnie serwer GitLab. To tam będziemy przechowawać nasza zdalną wersję projektu i tam będziemy wrzucać nasze najnowsze zmiany, oraz kolejne wersje programu.
A jak sobie te czynności zautomatyzujemy i oskryptujemy, to będzie to niebywale wygodnie i nowoczesnie! No to do dzieła!
No i GIT!
Na początek musimy sobie pobrać i zainstalować samego Gita, najlepiej z oficjalnej strony. Nie będe tutaj opisywał jak to zrobić, bo nie jest to nic trudnego, a takich poradników jest na sieci setki. Więc dla naszych potrzeb zakładam, że już właśnie to zrobiłeś. Masz zainstalowanego Gita i możesz go sobie wywoływać z linii poleceń o tak:
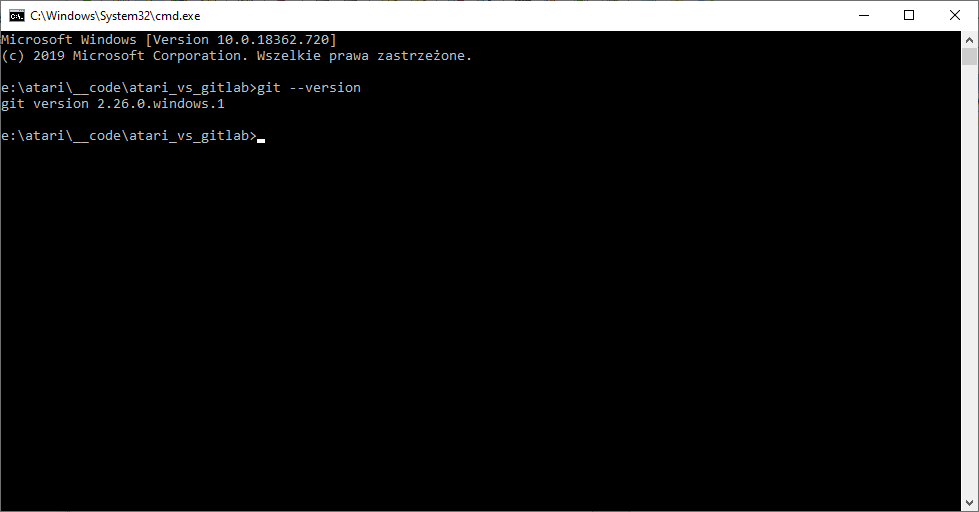
Oczywiście Twoja wersja Gita może być inna, ale o ile ma z przodu dwójkę lub więcej, to nie powinno być problemów z dalszą częścią tego poradnika.
Wraz z instalacją pakietu git dla systemu Windows, otrzymujemy tez darmowe narzędzie zwane git-bash:
Jest to zamiennik Widowsowego okna poleceń na konsolę zgodną z linuxowym bashem. Serdecznie go polecam, bo posiada wygodne skróty, historie poleceń, kolorowanie i takie tam różne bajery. Ja dla dalszych potrzeb tego poradnika będę używał właśnie basha, ale jak uprzesz się korzystać ze standardowego Windowsowego cmd, to tez nie powinno być problemów.
Jeżeli ktoś ma już jakieś pojęcie o Gicie, lub o innym systemem kontroli wersji, może zapytać: po co bawimy się konsolą, skoro od dawna są już narzędzia, które mają GUI i gdzie można sobie wszystko wyklikać? No owszem, są. Ale z doświadczenia wiem, że jak dobrze zrozumiemy co dzieje się "pod maską", to będziemy później jeszcze swobodniej posługiwać się każdym napotkanym narzędziem do obsługi Gita. Wiec tutaj będziemy obsługiwać Gita z konsoli, a jeżeli potrafisz i masz ochotę robić to innym sposobem, to nic nie stoi na przeszkodzie.
Skoro już mamy zainstalowanego Gita, to załóżmy sobie katalog z naszym pierwszym projektem i skonfigurujmy nasze pierwsze Gitowe repozytorium.
Najpierw zakładamy katalog. Niech się zwie test1. (Dla windowsowego cmd zamiast mkdir, używamy komendy md)
mkdir test1Przechodzimy do naszego katalogu:
cd test1I teraz inicjujemy nasze repozytorium.
git init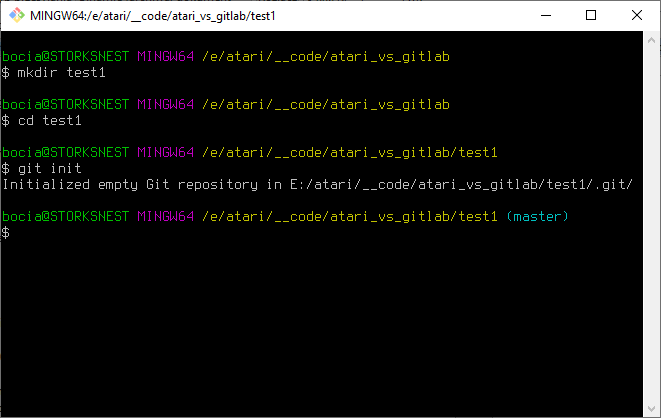
Od tej pory nasz katalog test1 jeden jest "objęty" systemem kontroli wersji. Teoretycznie nic się nie zmieniło, ale można zauważyć dwie rzeczy:
- pojawił się napis (master) w oknie basha - przy nazwie naszego katalogu. Dzięki temu widać, że pracujemy na gałęzi głównej naszego repozytorium. Co to naprawdę oznacza, to dopiero za chwilę.
- jeżeli mamy w systemie widoczne ukryte katalogi, to możemy dostrzec, że w naszym folderze pojawił się nowy folder o nazwie .git
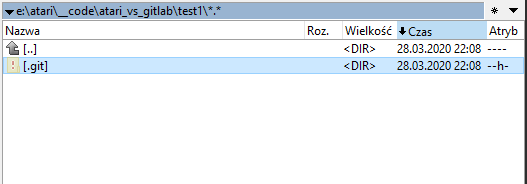
To właśnie w tym katalogu przechowywana jest nasza prywatna kopia całego repozytorium, i tutaj system kontroli wersji będzie pamiętał wszystkie nasze zmiany, wersje i działania. I to w zasadzie tyle co powinieneś o tym katalogu wiedzieć. Prawdopodobnie nigdy nie będziesz musiał tutaj zaglądać, ani nic w nim robić ręcznie. Zatem zapominamy o nim :)
No ale żeby można było cokolwiek zmieniać i synchronizować to potrzebujemy plików! Bez plików nie ma zabawy, więc załóżmy sobie w tym folderze jakiś plik. Niech będzie to plik README.md, a dlaczego właśnie taki, to o tym za chwilę.
README.md
# Testowe Repozytorium Plików
Ten projekt to tylko przykład jak można śledzic zmiany w plikach.
Nic więcej tu chyba nie trzeba pisać, chociaż kusi. Mamy pierwszy plik w naszym repo i zobaczmy co na to powie nasz git. Aby w dowolnym momencie sprawdzić stan naszego repozytorium używamy komendy:
git status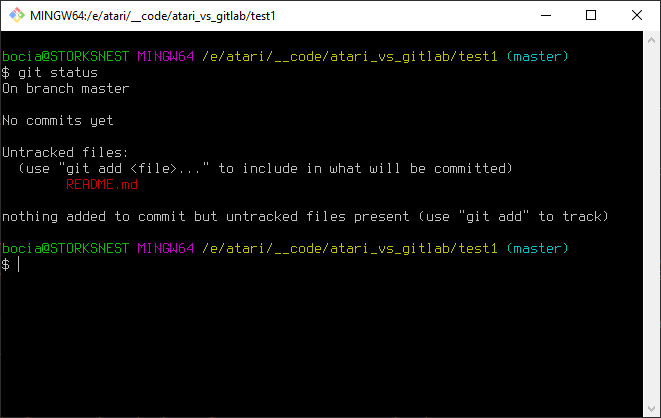
Sporo informacji, więc lecimy po kolei od góry:
On branch master Oznacza, że pracujemy w głównej gałęzi repozytorium, zwanej master. Dokładne działanie mechanizmu branchy, czyli gałęzi nie jest tematem tego przewodnika, ale generalnie gałęzie wykorzystuje się zazwyczaj przy pracy równoległej kilku programistów, lub przy testowaniu jakiejś nowej funkcjonalności której nie chcemy od razu wrzucać do głównej wersji programu. Dla naszych skromnych potrzeb będziemy pracować tylko na gałęzi głównej master i tyle informacji nam na razie wystarczy.
No commits yetNie było żadnych commitów. No nie było. A commit to będzie nasza najczęstsza czynność wykonywana podczas pracy z gitem więc warto wiedzieć co oznacza. Commit to w najprościej mówiąc zatwierdzenie zmian wprowadzonych w naszym repozytorium. Każdy wykonany commit będzie punktem w historii naszego repozytorium do którego możemy się cofnąć, oraz możemy porównywac zmiany kodu pomiędzy poszczególnymi commitami. Dopóki nie wykonamy commita, nasze repozytorium nie będzie wiedziało nic o tym, co zmieniło się w naszych plikach, więc dobrą praktyką jest wykonywanie commita po każdej większej zmianie, poprawie błędu, lub dodaniu nowych działających elementów do naszego kodu. Juz z pewnością nie możesz się doczekać swojego pierwszego commita i wierz mi, że to już niedługo. Na razie czytamy dalej:
Untracked files:
(use "git add <file>..." to include in what will be committed)
README.mdTutaj mamy listę naszych "nie-śledzonych" plików. Co to oznacza? Dokładnie to co napisane jest poniżej:
nothing added to commit but untracked files present (use "git add" to track)Czyli nasz nowy plik jest w katalogu, ale nie jest śledzony. Czyli nie znajdzie się w najbliższym commicie. Każdy plik który chcemy żeby był częścią naszego rezpozytorium i którego wersje ma śledzić nasz Git, musi zostać wcześniej dodany komendą git add. Możne te pliki dodawać pojedynczo:
git add README.mda można też hurtem, podając jako listę plików kropkę, czyli bieżący katalog:
git add . 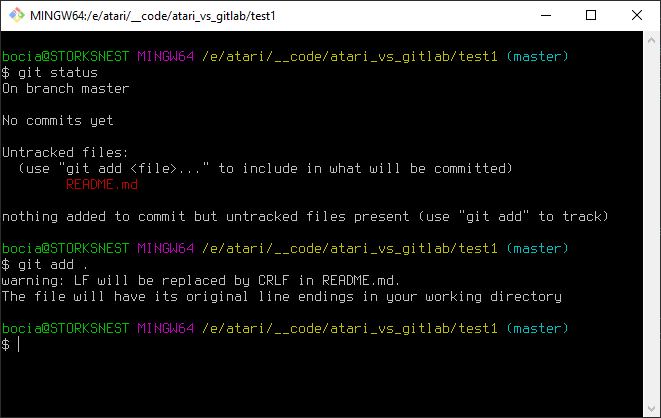
Komunikat który tutaj widzimy niekoniecznie pojawi się u Ciebie. Oznacza on, że git rozpoznał, ze ma do czynienia z plikiem tekstowym i zamienił znaki końca linii stosowane przez mój edytor (LF), na standardowe windowsowe (CRLF). To kwestia moich ustawień systemowych i nie musimy sie tym przejmować. Tak jest dobrze i niech sobie tak robi.
Ale wynikiem naszej operacji jest to co chcieliśmy. Plik README.md został dodany do naszego repozytorium i od teraz wszystkie zmiany jego zawartości będą śledzone przez Gita. Sprawdźmy co powie nam teraz git status:
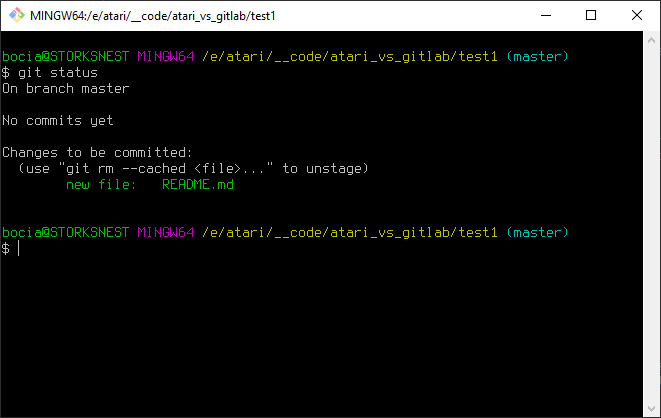
No i doskonale:
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: README.mdOd teraz nasz następny commit będzie zawierał zmiany w pliku README.md. Czyli nadeszła wiekopomna chwila, w której wykonamy naszego pierwszego commita.
ZBIERA MI SIE NA COMMITY
Commity w systemie git będziemy robić często, a wykonujemy je w ten sposób:
git commit -m 'Twój opis zmian'Ale zanim wykonasz to polecenie, to pochylmy się na chwilę nad opisem zmian. Parametr -m 'Twój opis zmian' jest obowiązkowy i BARDZO WAŻNY. W tym miejscu w sposób zwiezły, ale dokładny opisujemy jakie zmiany względem poprzedniej wersji zawiera nasz commit. Warto w tym miejscu poświęcić kilka sekund lub nawet minut na dobre wymyślenie opisu, który po czasie będzie dla nas czytelny i zrozumiały. Ja sam nadal się tego uczę, i często żałuję potem, że zrobiłem to byle jak. Przykładowo trafiając na opis 'drobne poprawki i błedy' za cholere nie wiem co zrobiłem, a już czytając 'poprawiony kursor i znikający kolor w dli' przynajmniej wiem czego mniej więcej dotyczyły dokonane w tym commicie zmiany.
Zatem uzbrojeni w tę wiedzę, wykonajmy pierwszego commita:
git commit -m 'Dodanie pliku README.md'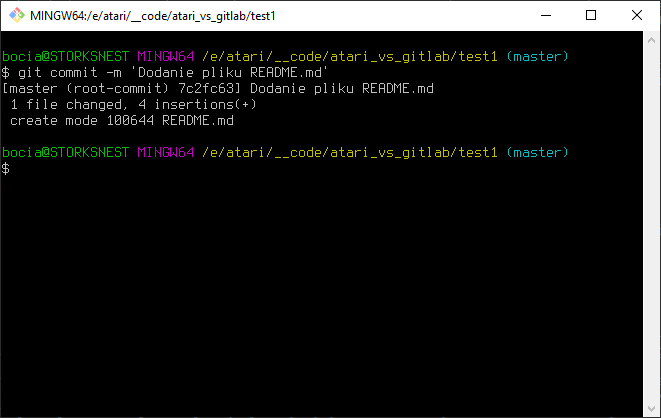
Widzimy że dodany został jeden nowy plik i "4 insertions", co oznacza, że w pliku tym pojawiły się 4 nowe linie. Linia 'create mode 100644 README.md' pokazuje jakie uprawnienia do tego elementu przechowuje sobie nasze repozytorium i dla naszych potrzeb i na tym etapie ta informacja jest dla nas nieistotna. Git robi to sobie sam i zazwyczaj robi to dobrze, więc nie ma się co wtrącać. Sprawdzmy stan naszego repo:
Nothing to commit, working tree clean! komunikat ten oznacza, że od czasu naszego ostatniego commita nie zmieniło się nic. Taka jest smutna prawda. Ale mamy już nasz pierwszy śledzony plik! Wykonaliśmy pierwszego commita, więc mamy jakiś punkt startowy do śledzenia dalszych zmian. Zatem nie pozostaje nam nic innego jak coś zmienić.
Pewnie Wam umknęło, ale w pliku README.md sprytnie przemyciłem drobny błąd. W wyrazie "śledzić" brakuje kreseczki nad literą c. Poprawmy to niezwłocznie i sprawdźmy co teraz powie nam git status:
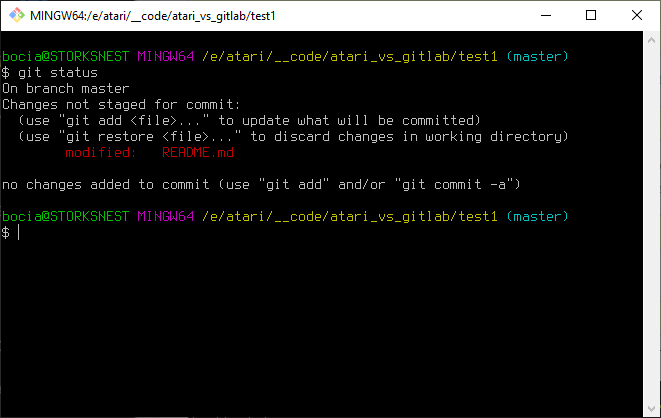
Widzimy, że nasz plik został zmodyfikowany, ale zmiany nie zostały "zastejdżowane" do commita. Oznacza to, że git wie że cos pozmienialiśmy, ale żeby to zatwierdzić musimy tę zmianę dodać do następnego commita. i tak jak poprzednio przy użyciu komendy git add. I jeżeli w tym momencie nie mamy już więcej zmian do dokonania, to moglibyśmy zrobić git add i zacommitować aktualny stan. Ale żeby nie było tak prosto, to dodamy sobie jeszcze jakieś pliki i dopiero wtedy zatwierdzimy ("zastejdżujemy") i wykonamy kolejnego commita.
ALE GDZIE TO ATARI?
Na razie w kółko nawijam o Gicie, a poradnik miał być też o Atari. No to dorzucamy sobie do naszego projektu fantastyczny program w assemblerze, który wypisze nam na ekranie hello world!.
hello.asm
EOL = 155
ICCMD = $342
ICBUFA = $344
ICBUFL = $348
PUTBT = %1011
JCIOV = $e456
org $600
main
ldx #0
lda #PUTBT
sta ICCMD,x
lda #<txt
sta ICBUFA,x
lda #>txt
sta ICBUFA+1,x
lda #<txtlen
sta ICBUFL,x
lda #>txtlen
sta ICBUFL+1,x
jsr JCIOV
jmp *
txt dta 'Hello World!',EOL
txtlen = *-txt
run mainNo i spróbujmy sobie go skompilować:
/e/atari/mads/mads.exe hello.asm
Z pewnością u Ciebie ścieżka do assemblera będzie inna, a nieszczęśnicy korzystający z Windowsowej linii komend będą ją musieli wpisać w takiej postaci:
e:\atari\mads\mads.exe hello.asmZałóżmy, że wiecie gdzie macie swoje narzędzia, albo też skompilujecie to jakoś po swojemu, ale efekt będzie ten sam: oprócz README i pliku asm, mamy w naszym katalogu plik wykonywalny hello.obx.

No i super! Zobaczmy status:
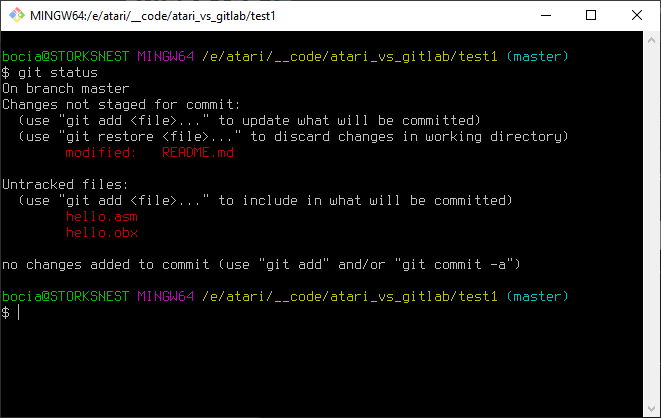
Wypadało by teraz dodać do commita wszystkie zmiany poleceniem "git add ." i commitować na całego. Ale załóżmy sobie dla utrudnienia, że chcemy w naszym repozytorium przechowywac i śledzić tylko zmiany w plikach źródłowych. Po jaką cholere nam zmiany w binarkach?
Teoretycznie moglibyśmy ręcznie dodać tylko pliki które nas interesują:
git add hello.asm README.mdPotem już tylko commit i to by nawet zadziałało. Ale przecież o wiele wygodniej jest dodawac pliki hurtem przy pomocy kropki, prawda? A już szczególnie jak mamy dużo plików i sporo zmian. No i za każdym razem trzeba pamiętać, aby przypadkiem nie dodać naszej binarki do commita. To byłoby cholernie upierdliwe... gdyby tylko dało się jakoś ukryć niektóre pliki przed tym Gitem?
GITIGNORE? BIORE!
Oczywiście że się da. I to niezwykle prosto i wygodnie. Wystarczy w głównym katalogu naszego projektu założyć plik o nazwie:
.gitignoreI kropka na początku tego pliku jest niezwykle ważna. Bez niej nie zadziała!!!
Ten plik to rodzaj filtra, instruujący Gita które pliki lub nawet katalogi ma omijać - ignorować. Po prostu umieszczamy wewnątrz pliku linia po linii nazwy plików, które mają stać się "niewidzialne". Zatem na nasze skromne potrzeby najprostszy plik .gitignore mógłby wyglądać tak:
.gitignore
hello.obxI gotowe! To zadziała. Ale naszej wygody możemy korzystać z symboli wieloznacznych takich jak * i ?, oraz z komentarzy, więc przygotujmy sobie porządny uniwersalny filtr, który będziemy mogli wykorzystywać także w kolejnych projektach.
.gitignore
# Ignoruj różne typy plików binarnych
*.obx
*.xex
*.comZapisujemy nasz plik i od teraz git nie będzie widział, żadnych z plików z rozszerzeniami obx, xex ani com. No to sprawdźmy status:
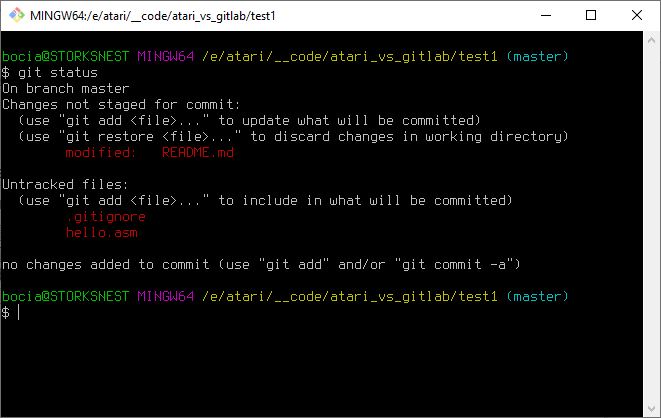
Elegancko. Pomimo, ze plik .gitignore nie jest jeszcze dodany do następnego commita, to już działa. Znikł nam z listy plik hello.obx, pomimo tego, że nadal jest w katalogu naszego projektu. Czy to nie piękne?
W ten sposób możemy tez z wykluczać całe katalogi. Przykładowo, aby ignorowac cały folder w projecie, dodajemy taki wiersz:
test/I teraz katalog test wraz z zawartością staje się niewidzialny. Wiecej o pliku .gitignore mozesz sobie znaleźć w sieci (jeśli bedziesz potrzebować), a na razie tyle informacji spokojnie Ci wystarczy.
No dobra. Mamy nasz super działający program, wykluczyliśmy binarkę z repo, czas zatwierdzić nasze zmiany! To lecimy:
git add .
git commit -m 'nowe pliki hello.asm i .gitignore, literówka w pliku README'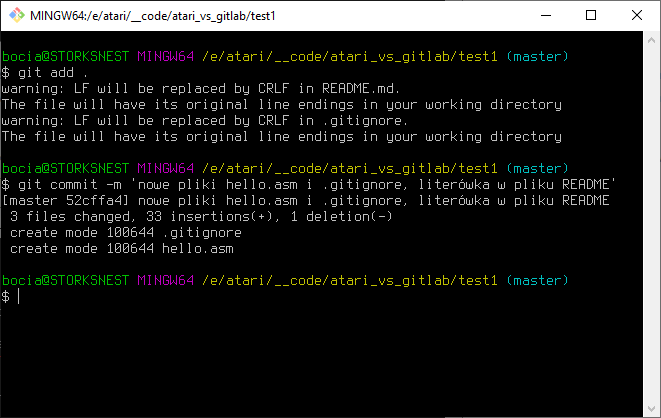
Fajnie. Porobione. Ale gdzie ta cała kontrola wersji? Po co to wszystko? Pamiętaj, ze na razie wszystko co robiliśmy, robiliśmy lokalnie. Historia zmian dotyczy tylko naszej kopii. Ale już możemy sobie ją przeglądać:
git log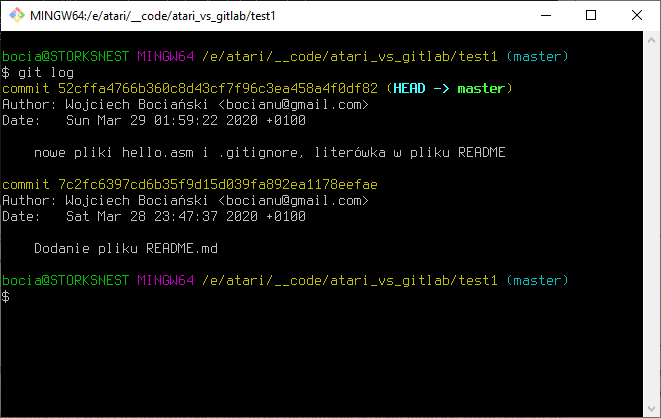
Widzimy tutaj wszystkie nasze commity, od najnowszego do najstarszego wraz z opisami. Ale nadal nie widać zmian w poszczególnych plikach. Oczywiście da się to wszystko wyświetlić również z linii poleceń różnymi skomplikowanymi komendami, ale to nie to ma być treścią tego poradnika, my do tego celu wykorzystamy GitLaba! Już i tak rozpisałem się o Gicie więcej niż chciałem. To szybko podsumujemy naszą wiedzę z Gita używanego lokalnie i zaraz przejdziemy do nastepnej części.
- Zawsze pamiętaj aby przed commitem dodać do niego wszytkie zmiany, które chcesz zatwierdzić.
- Pliki których zmian nie chcesz śledzić i nie chcesz ich synchronizować wrzuć do .gitignote
- Commitując zmiany pamiętaj o dobrym opisie, później będziesz sam sobie wdzięczny.
Czyli nasz workflow zazwyczaj będzie wyglądał tak:
Krok 1: kończymy jakis etap pracy nad programem (dodajemy coś nowego, naprawiamy błąd itp...)
Krok 2:
git add .
git commit -m 'opis co zrobiliśmy'I to w zasadzie tyle jeżeli chodzi o podstawową obsługę gita. A teraz na koniec części pierwszej podam Wam jeszcze jeden Pro-Tip, który ułatwi nam nieco pracę. Jeżeli chcemy dodać do commita wszystkie pliki (oczywiście prócz tych w .gitignore) to możemy zamiast git add . użyć parametru -a w komendzie git commit:
git commit -a -m 'opis zmian'Jest to równoważnie z dodaniem wszystkich zmian w plikach do commita i wykonaniem go.
Ja już wspominałem wcześniej, wiele środowisk programistycznych oraz niektóre edytory (VSCode, Atom, Eclipse, Sublime) posiadają zintegrowaną obsługę Gita. Tam wszystkie te operacje sobie "wyklikamy". Ale zawsze warto wiedzieć, co tak naprawdę się robi i co się dzieje pod spodem ;) Stąd ten cały przydługi wstęp.
Dobra, chyba w końcu nadszedł czas aby pokazać jak działa repozytorium zdalne i synchronizacja naszego projektu z serwerem Gitlab, który nam wszystko bardzo ułatwi i uporządkuje. A dodatkowo będzie naszym zdalnym backupem, kompilatorem, i wszechstronnym narzędziem do zarządzania naszym fantastycznym projektem.
Ale to dopiero w następnęj części!