

ATARI vs Gitlab - część 2
Data publikacji:31.03.2020
GITLAB HERO
Jak już wcześniej wspomniałem, Git jest także repozytorium zdalnym, co oznacza, że oprócz lokalnego śledzenia zmian w naszym projekcie, możemy je synchronizować z repozytorium zdalnym, czyli mamy kopię naszego projektu, wraz całą historią zmian. I do tego repozytorium zdalnego możemy podłączać się z dowolnego innego komputera, wykonywać na nim kolejne zmiany, a te zostaną przeniesione podczas najbliżej synchronizacji na nasz sprzęt lokalny. Świetna sprawa. Zdarza mi się czesto pracować nad jednym projektem z kilku maszyn: stacjonarka w domu, laptop, netbook. Gdybym za każdym razem miał pamietać na którym sprzęcie mam najnowszą wersję to bym chyba oszalał. A tak, synchronizuje sobie moje ostatnie zmiany z GitLabem i po przesiadce na kolejnego kompa, jednym poleceniem synchronizuje swoją lokalną kopię z najnowszą wersją na serwerze. I mam wszystko świeżutkie i pachnące nowością. Chciałbyś tak, prawda?
No to rejestruj sie na GitLabie! Może to tez być GitHub albo inny hosting obsługujący repozytoria Gita. Ale ja swój poradni oprę o GitLaba, bo jego używam, więc jak zdecydujesz się na coś innego, to screeny moga nieco nie pasować, i pewnie bedą pewne różnice, ale wierzę że sobie poradzisz. ;)
Rejestracja na GitLabie jest darmowa i pozwala nam na nieograniczona ilość prywatnych i publicznych repozytoriów, co jest w zupełności wystarczającą opcją jak na moje potrzeby. Jedynym istotnym ograniczeniem wersji darmowej, które może nas dotyczyć, jest ograniczenie do 2000 minut miesięcznie na runnery, które będą odpowiedzialne za kompilowanie naszego kodu. Mnie się jeszcze nie udało wykorzystać całości w żadnym miesiącu, ale kto wie?
Zakładam, że dokonałeś już rejestracji w serwisie, więc możemy zaczynać!
Stwórzmy sobie nowy projekt, czyli repozytorium z którym zsynchronizujemy nasz katalog projektu z poprzedniej częsci.
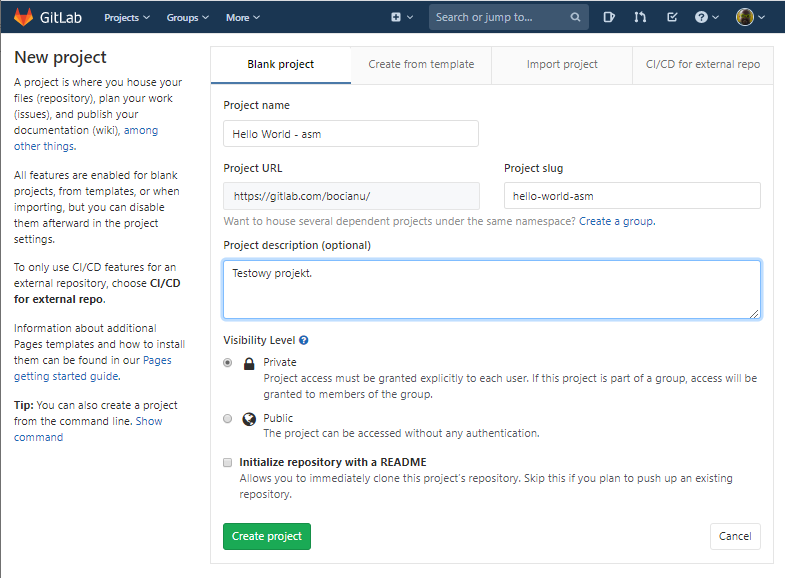
Wprowadzamy w zasadzie tylko nazwę projektu, i opis, a resztę możemy pozostawić bez zmian. No chyba, ze od razu chcecie, aby Wasz projekt był publiczny i wszyscy mogli sobie zaglądać do kodu i go pobierać. Jak tam wolicie. Tę właściwość można zawsze zmienić później w ustawieniach projektu.
Nie musimy zaznaczać checkboxa "Initialize repository with a README", bo przecież sami zrobiliśmy już sobie nasz plik README wcześniej!
No to klikamy na przycisk Create project i... trafiamy na takie czary:
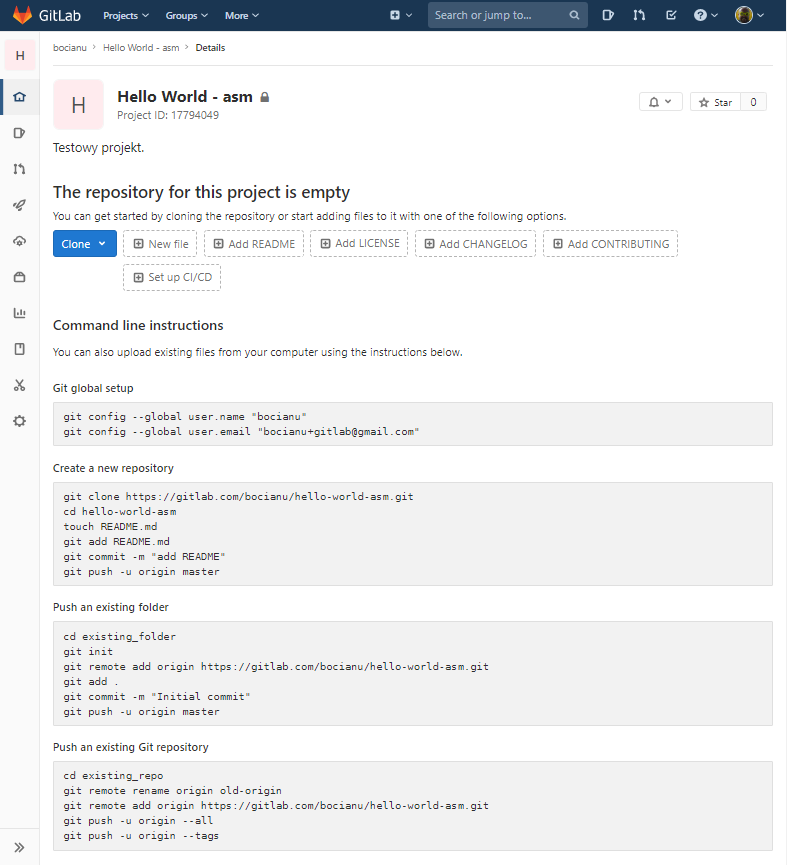
Tak, teraz nadszedł czas, aby nasz lokalny folder zsynchronizować z nowo założonym projektem w GitLabie. System podpowiada nam kilka różnych opcji, omówimy sobie je po kolei. U góry ekranu możecie trafić na takie okienko:

Oznacza to, że nie będziemy mogli korzystać z SSH do synchronizacji naszych plików z repozytorium, dopóki nie dodamy kluczy SSH w naszym profilu. No trudno. Na razie olejemy tę opcję i będziemy do synchronizacji korzystać z HTTPS. Jedyny mankament to to, że będziemy musieli czasem podawać nasze hasło do GitLaba. A jak ktoś bardzo chce sobie skonfigurować SSH i działać bez hasła, to trzeba wejść do ustawień użytkownika Gitlab i w zakładce SSH keys dodać swój wcześniej wygenerowany klucz. Jest tam nawet intrukcja jak je wygenerować. Ja na nasze potrzeby pozostane przy HTTPS, żeby było prościej. Zakładam, że pamiętacie hasło do Gitlaba i jak o nie zapyta czasem Git, to nie spanikujecie.
Wracamy więc do opcji synchronizacji naszego projektu, które daje nam GitLab:
You can get started by cloning the repository or start adding files to it with one of the following options.Z tej opcji skorzystalibyśmy w przypadku, gdy chcemy sklonować istniejące już zdalne repozytorium, lub ręcznie dodać jakieś predefiniowane plikie, takie jak README lub LICENSE... Czyli nie. To nie jest opcja dla nas.
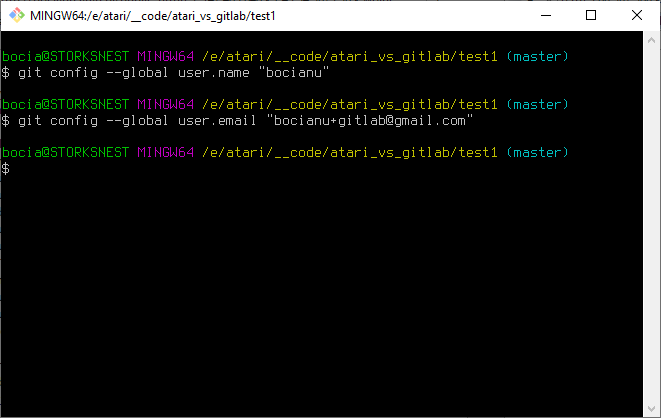
You can also upload existing files from your computer using the instructions below.O to to! Chcemy dodać pliki z naszego komputera. Czyli najpierw musimy poinstruować naszego lokalnego gita kim jesteśmy, żeby GitLab mógł nas zidentyfikować:
git config --global user.name "bocianu"
git config --global user.email "bocianu+gitlab@gmail.com"Oczywiście w cudzysłowach musisz podać swoją nazwę użytkownika GitLab, oraz swój adres na który zainstalowałeś to konto.
A teraz następny krok:
Create a new repositoryTo możemy pominąć - nie chcemy zakładać całkiem nowego repozytorium u siebie. Tę opcje przerobimy w trzeciej części naszego poradnika. My chcemy podłączyć już istniejący folder projektu.
Push an existing folderO tak, to wygląda na nasz przypadek. Przeanalizujmy sobie kolejne kroki linijka po linijce:
cd existing_folderNo zakładam że mamy już basha (lub cmd) otwartego w naszym katalogu, więc ten krok pomijamy.
git initTo już zrobiliśmy. Mamy już zainicjowane lokalne repozytorium. Pomijamy.
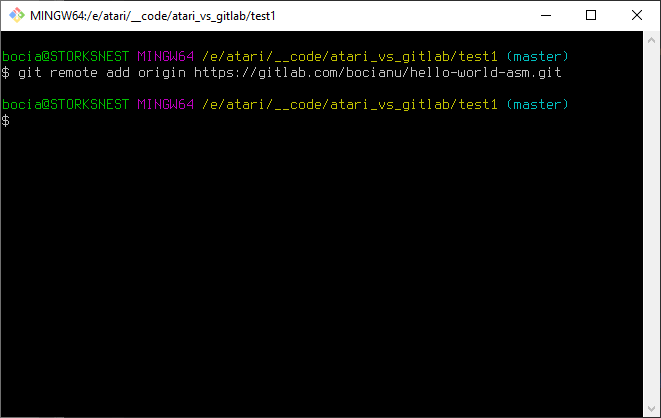
git remote add origin https://gitlab.com/bocianu/hello-world-asm.gitTa linia instruuje lokalnego Gita gdzie znajduje się nasz zdalny projekt. Tego nie możemy pominąć:
Dwa kolejne polecenia, powinny wyglądać znajomo:
git add .
git commit -m "Initial commit"Oczywiście musielibyśmy je wykonać, gdybyśmy zmienili cokolwiek od ostatniego commita, ale my jesteśmy świeżo po commicie, co można sprawdzić komendą.... oczywiście git status:
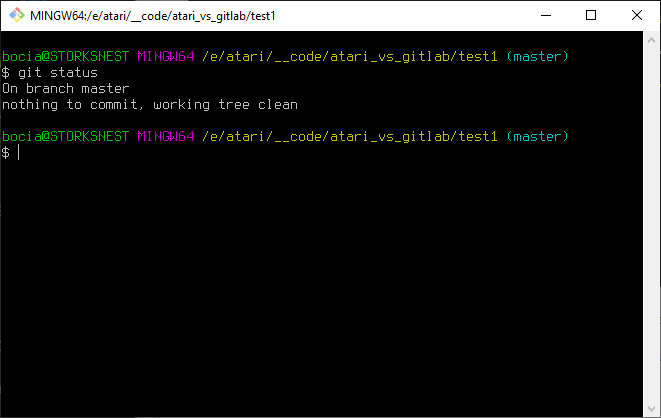
Więc przechodzimy od razu do ostatniego punktu. Git push!
git push -u origin master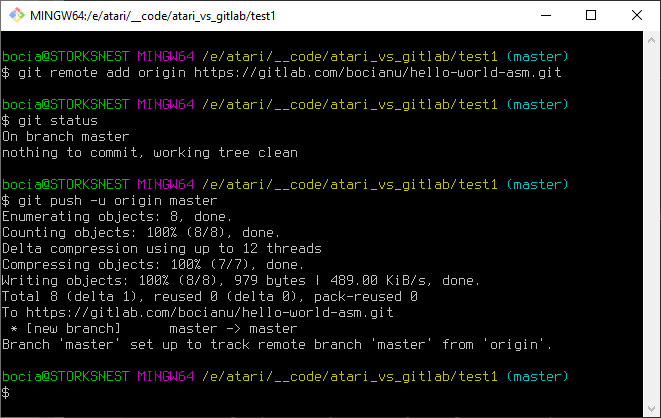
Poleceniem git push będzie naszym drugim - zaraz po commicie - najczęściej używanym poleceniem. Jak sama nazwa sugeruje, "wpycha" ona nasze lokalne zmiany do zdalnego repozytorium. Parametr -u origin master podajemy tylko za pierwszym razem i wskazuje on do jakiej gałęzi zdalnego repozytorium chcemy się domyślnie synchronizować. Po naszym kolejnym commicie wystarczy już samo git push i wszystkie nasze zmiany polecą wesoło na zdalny serwer.
No to zobaczmy teraz jak po naszym pushu wygląda projekt na GitLabie, Kliknij w nazwę projektu, albo odśwież okno GitLaba:
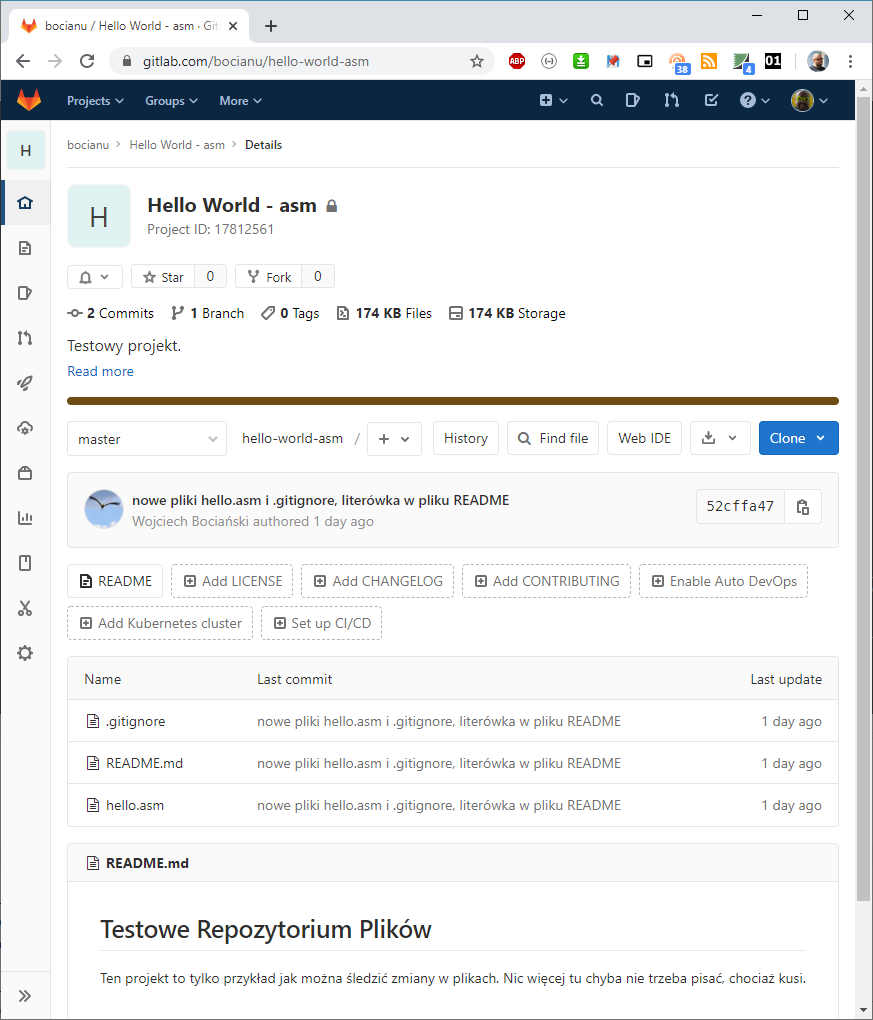
Widzimy wszystkie nasze pliki, a na samym dole wyświetlona jest zawartość pliku README.md. Ale dużo ciekawsze rzeczy są u góry! 2 Commits. Gitlab już wie, że robiliśmy 2 commity. 1 Branch - oznacza, że mamy jedną gałąź programu - master. 0 Tags. Tagami możemy sobie oznaczać konkretne momenty w historii naszego kodu, czyli np. kolejne oficjalne wersje.
Pamiętacie jak wyświetlaliśmy historię commitów poleceniem git log? Zobaczmy jak zgrabnie widać zmiany na GitLabie. Naciśnij przycisk History, ten w rzędzie pod grubą krechą:
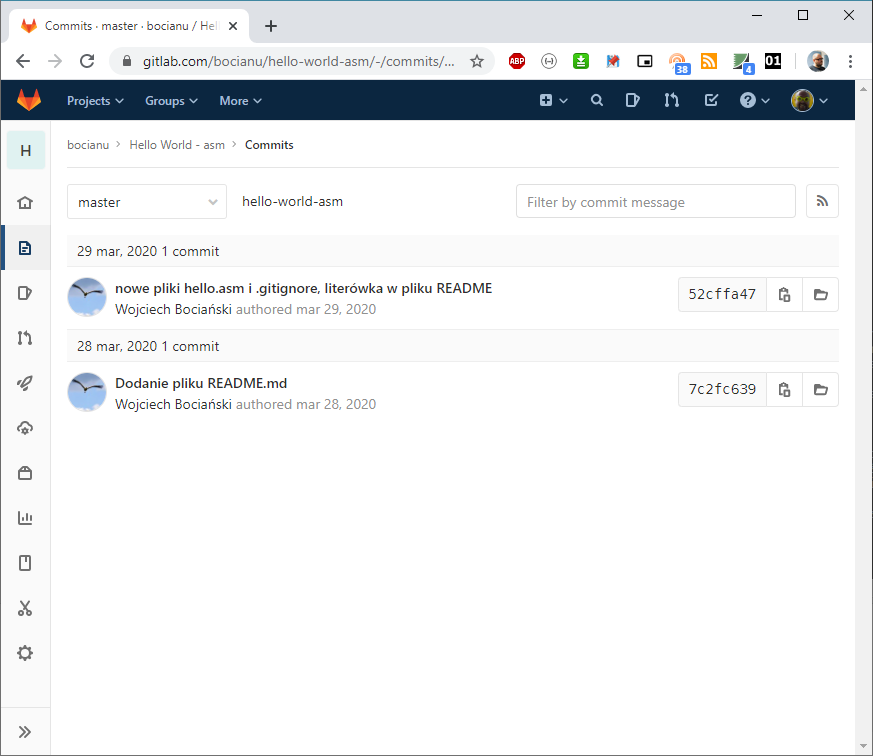
Wygląda to nawet podobnie to tego, co wyświetlił na git log. Ale kliknijmy sobie na opis pierwszego commita - "nowe pliki...":
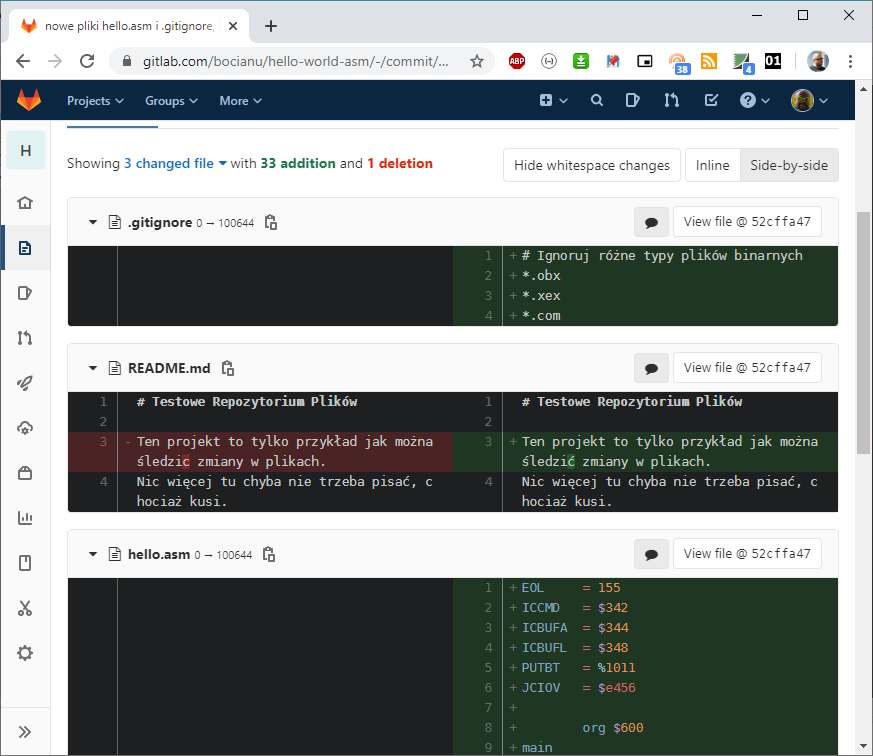
I mamy elegancki podgląd wszystkich zmian wprowadzonych w danym commicie. Przyciskami 'Inline' oraz 'Side-by-side' możemy zmienić sposób wyświetlania tych zmian, ale generalnie: wszystko co na zielono to dodane rzeczy, na czerwono usunięte.
GitLab ma wiele ciekawych funkcji, które warto poznać. O niektórych tu jeszcze opowiem, ale większość i tak będziecie musieli (albo i nie) poznać sami. Ja sam z pewnością nie znam wszystkich jego możliwości, a tylko te z których korzystam.
Jedną z ciekawszych funkcji, którą warto jeszcze pokazać jest 'Web IDE', czyli wbudowany w GitLaba edytor plików. Za jego pomocą możemy sobie wprowadzać zmiany w naszym kodzie, przy pomocy samej przeglądarki. Nie potrzebujemy instalować nic - nawet Gita. Spróbujmy!
Web IDE
Web IDE możemy uruchomić przyciskiem na stronie głównej projektu, gdzieś niedaleko przycisku History.
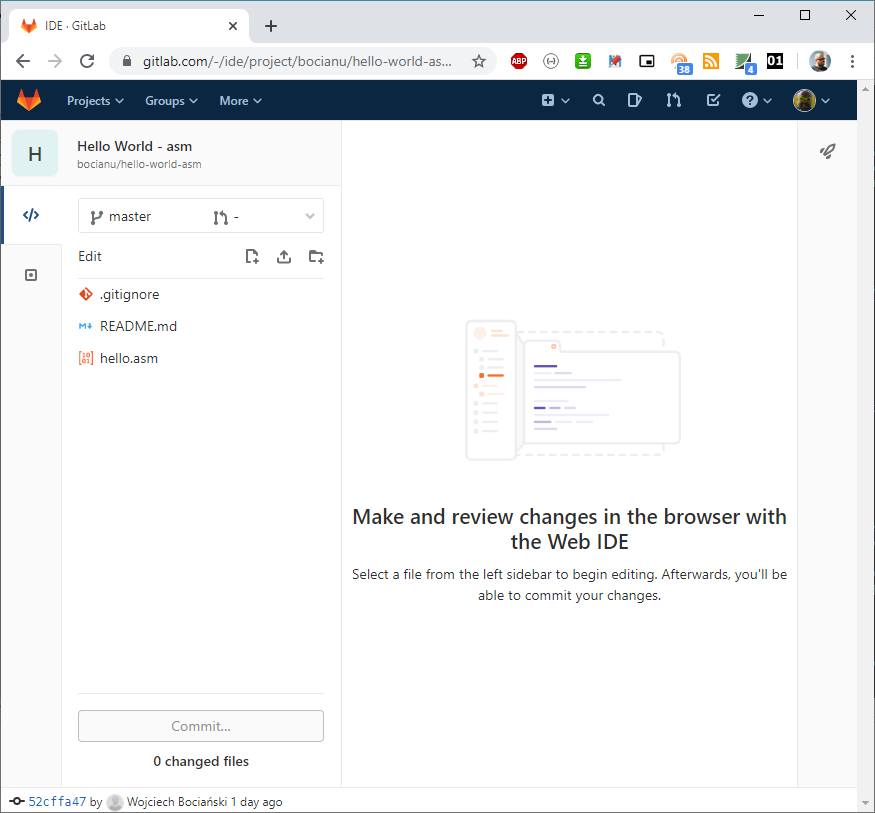
Po lewej stronie mamy do wyboru nasze pliki. Kliknij hello.asm i dodamy sobie komentarz na początku pliku.
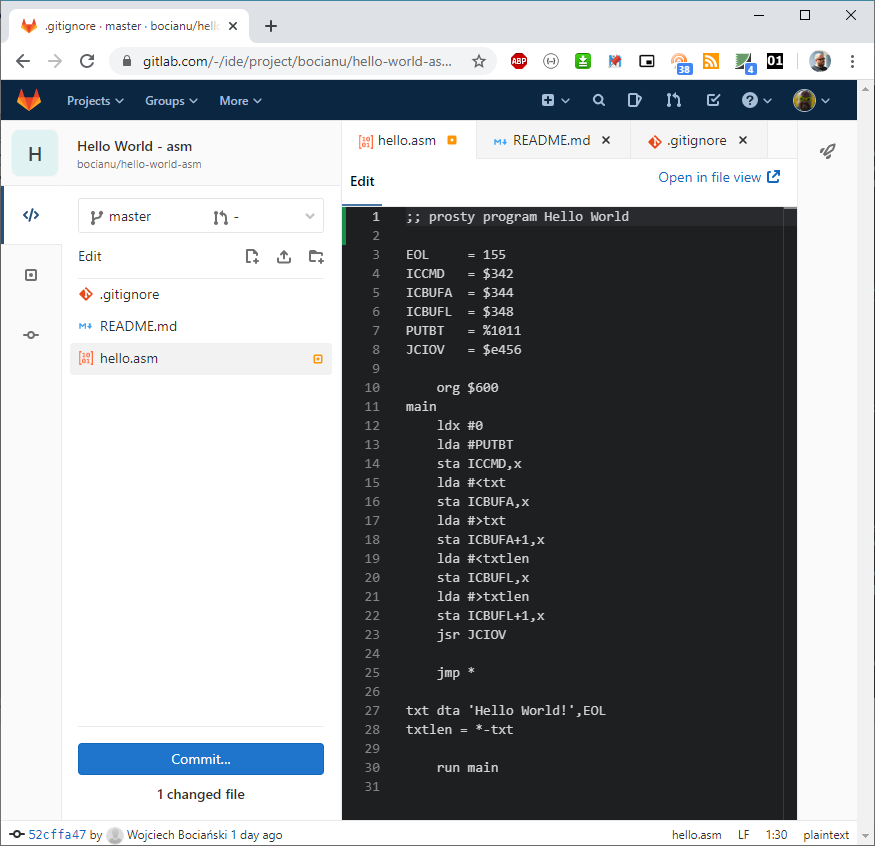
Zauważ, że nie ma nigdzie przycisku Save. Zamiast niego mamy przycisk Commit. Brzmi znajomo?
Ale zanim wykonasz commita, wybierz jeszcze plik README.md i zmień trochę jego zawartość:
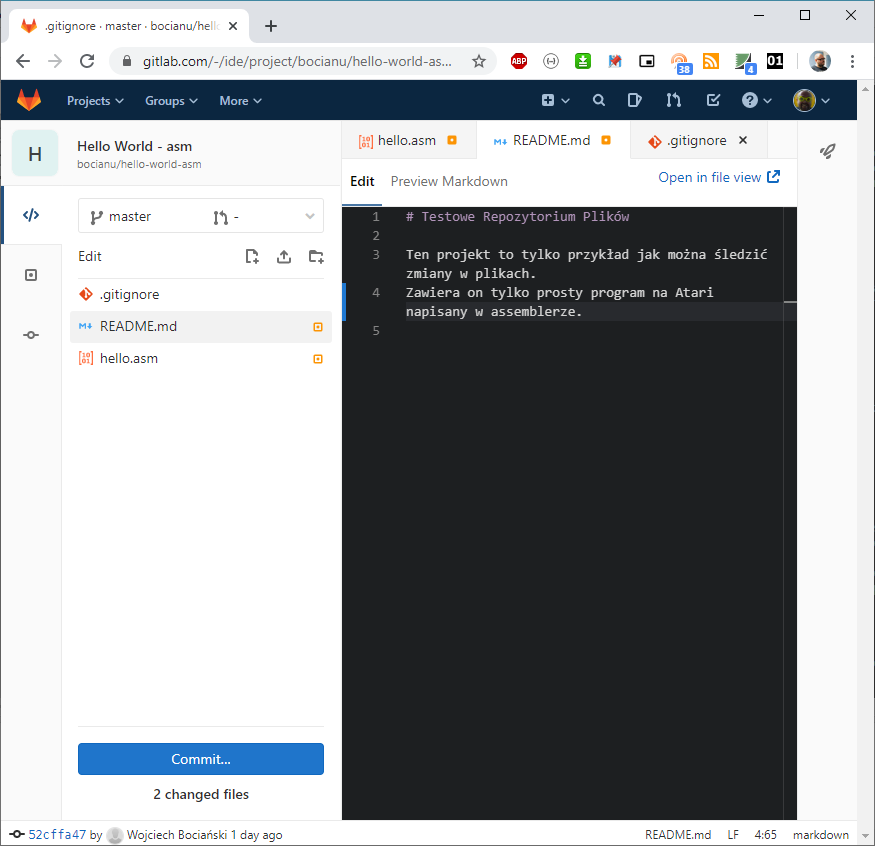
No i zmiany gotowe. Naciśnij Commit.
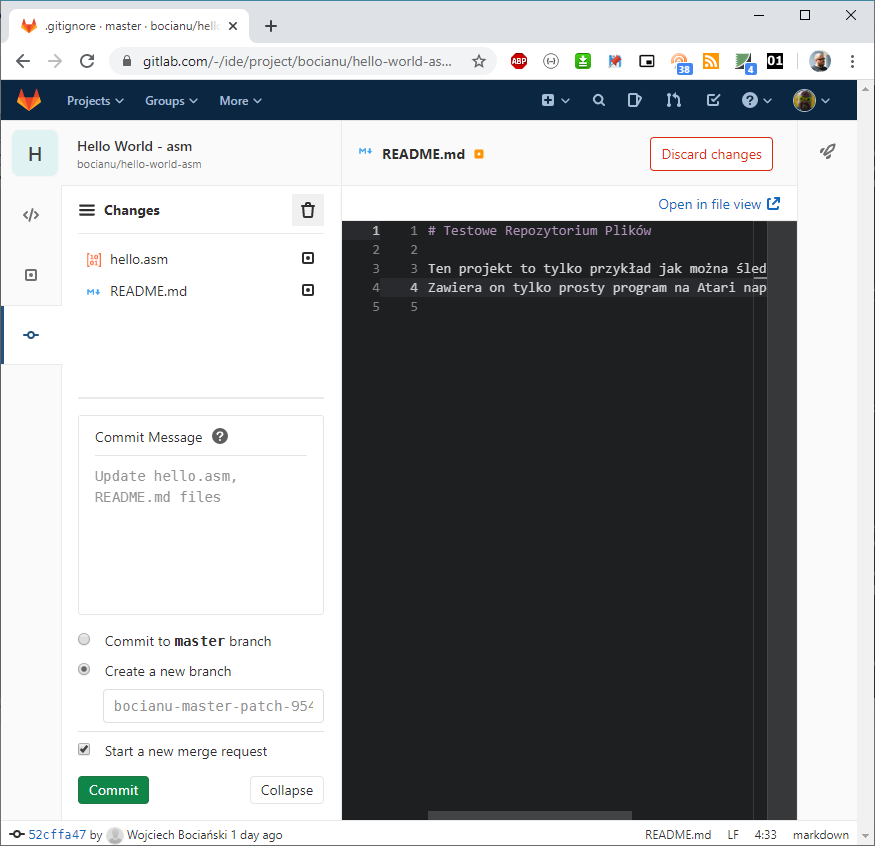
Jak widzisz, GitLab domyślnie proponuje utworzenie nowej gałęzi z bieżącymi zmianami. Miałem tu nie tłumaczyć co to są branche, ale dobra. W skrócie. Robiąc nowego brancha robimy takie jakby odgałęzienie od głównej linii kodu, i pracujemy jakby równolegle na jego kopii, nie naruszając w tym czasie gałęzi głównej master. Możemy sobie wykonywać dowolną ilość commitów do nowego brancha, robić zmiany które są niezależne od mastera. To dobra praktyka w przypadku gdy robimy jakąś dużą zmianę w kodzie, a już absolutnie niezbędne jak pracujemy nad jednym projektem w kilka osób. Ale co potem z tymi branchami? Na koniec, kiedy już jesteś pewnien, że wszystko co dodałeś (lub naprawiłeś) działa, to dopiero wtedy przerzucasz wszystkie zmiany ze swojej gałęzi do gałęzi głównej master. Ta operacja nazywa się Merge i nie będziemy jej tutaj omawiać. Na razie wystarczy, że wiecie że coś takiego jest i jak ktoś jest zainteresowany, to może sobie poczytać więcej na ten temat w dowolnym tutorialu do Gita. Tutaj tylko wrzucę kradziony obrazek, dla lepszego zobrazowania jak działają branche.
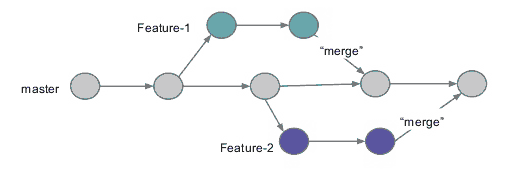
Bardzo fajny kurs na ten temat podrzucił też astrofor na forum, pozwolę sobie go tutaj także dorzucić: Learn Git Branching.
No więc wracając do naszego WebIDE, my nie zakładamy nowego brancha, tylko wrzucamy nasze zmiany prosto na mastera. Więc przełączamy na Commit to master branch:
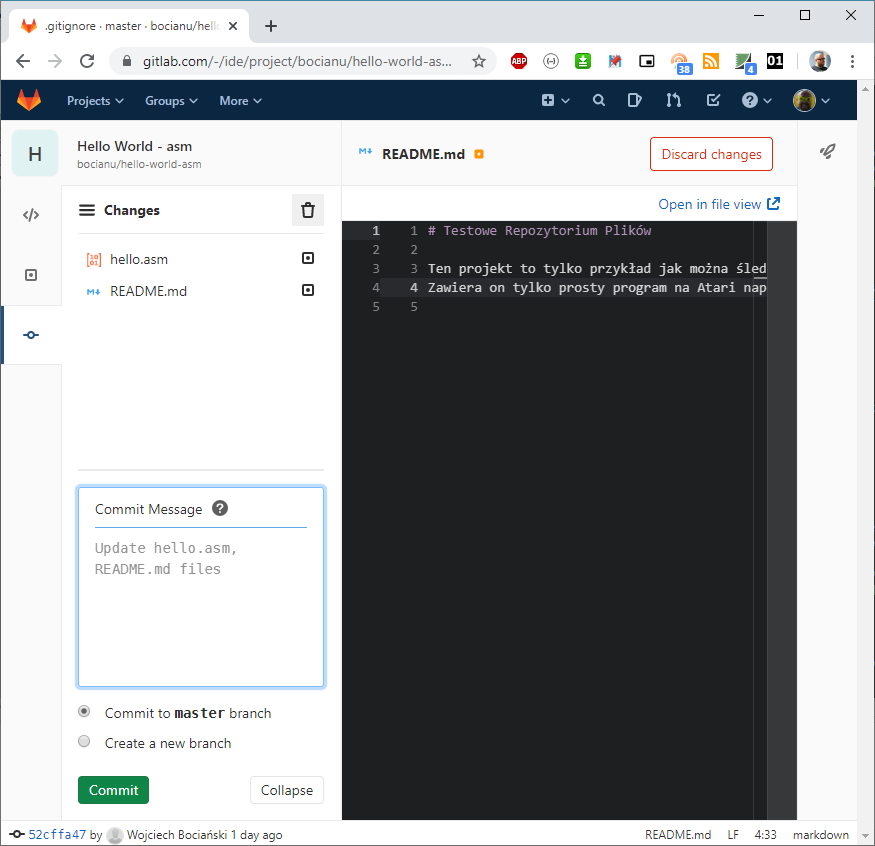
Jak widać GitLab podopowiada już nam opis commita, na bazie analizy naszych działań. I jak widać całkiem trafnie. Warto by było tylko uzupełnić informacje o to, czego te zmiany dotyczyły, więc możemy dodać coś w stylu
Update hello.asm: comment added, README.md: description fixed.I teraz ktoś powinien się oburzyć, dlaczego daję opis commita po angielsku, jak wcześniej było po polsku? I słusznie się oburzy. Od początku powinny być po angielsku, mój błąd. A dlaczego tak? A dlatego, że jeżeli zamierzamy udostępnić nasz kod, to może ktoś będzie chciał coś dopisać, lub przeanalizować. A wierzcie mi lub nie, ale więcej osób na świecie posługuje się angielskim niż polskim. Zasadę tę stosuje także - a nawet chyba przede wszystkim - do komentarzy w kodzie. Ja tak robię, aby nie ograniczać potencjalnych odbiorców tylko do Polski i Tobie polecam (ale nie ma musu).
No to dosyć gadania, commitujemy. Klik i commit poszedł. Przełączmy się ponownie na widok projektu i widać wyraźnie, że mamy już 3 commity. No i super. Wyedytowaliśmy sobie pliki w przeglądarce, jeszcze zaraz podłączymy sobie kompilator, żeby się nam wszystko pięknie budowało po każdej edycji. Ale moment...
Przecież nasz projekt lokalnie na komputerze nie wie nic o zmianach które zaszły w zdalnym repozytorium! No to sprawdzmy co się dzieje u nas w folderze test1 :) Najpierw status.
No nic nowego. Ale to dlatego, że nasze lokalne repozytorium jeszcze nie zostało zsynchronizowane ze zdalnym. Poznajmy nowe polecenie:
git fetch
git status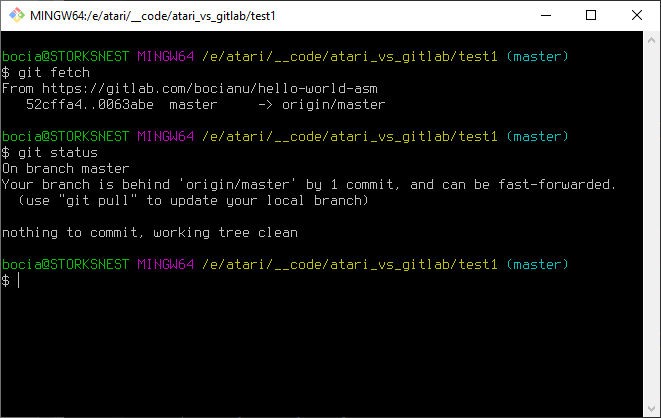
Co robi polecenie git fetch? Synchronizuje nasze lokalne repozytorium z repozytorum zdalnym. Co ważne, to polecenie jeszcze NIE ZMIENIA żadnych plików w naszym projekcie. Tylko aktualizuje zawartość swojego systemowego katalogu .git. Zatem zmiany które zaszły na serwerze zdalnym, już powinny być widoczne dla polecenia status. No i jak widać są!
Teraz, aby faktycznie przesunąć się w naszym drzewku projektu do ostatniego commita i zaktualizować lokalne pliki projektu do najnowszej wersji, wydajemy polecenie git pull, zgodnie z sugestią samego Gita:
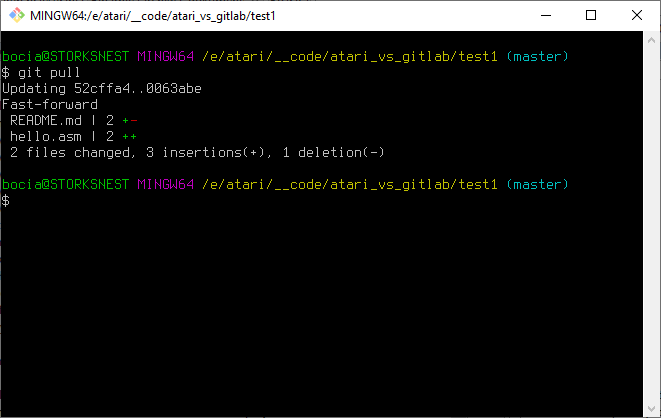
Ładnie widzimy jakie pliki się zmieniły i hop, już mamy u siebie najnowsze zmiany!
Zazwyczaj jest tak, że wiemy kiedy zmieniły sie nam pliki w zdalnym repozytorium, więc w codziennej pracy zwykle pomijam polecenia fetch i status. Od razu zasysam najnowszą wersje poleceniem git pull.
No dobra, nauczyliśmy się już podstaw pracy z Gitem, omówimy sobie jeszcze tylko jeden scenariusz, który może się Wam kiedyś przydać. Co w przypadku, kiedy mamy już jakiś rozpoczęty projekt na GitLabie, który edytujemy sobie na swoim komputerze stacjonarnym, a chcielibyśmy na nim popracować na laptopie na wczasach? Co wtedy?
KLONUJ!
Zasymulujmy sobie nowe środowisko, wystarczy że wyjdziemy z katalogu test1 i przejdziemy sobie do jakiejś innej lokacji. Oczywiście na nowym sprzęcie musielibyśmy zainstalować sobie Gita i jakiś edytor do kodowania, na przykład ten. Tutaj nie musimy.
Zatem mamy nowy katalog i chcemy zrobić sobie lokalną kopie repozytorium. Otwórz stronę projektu na gitlabie:
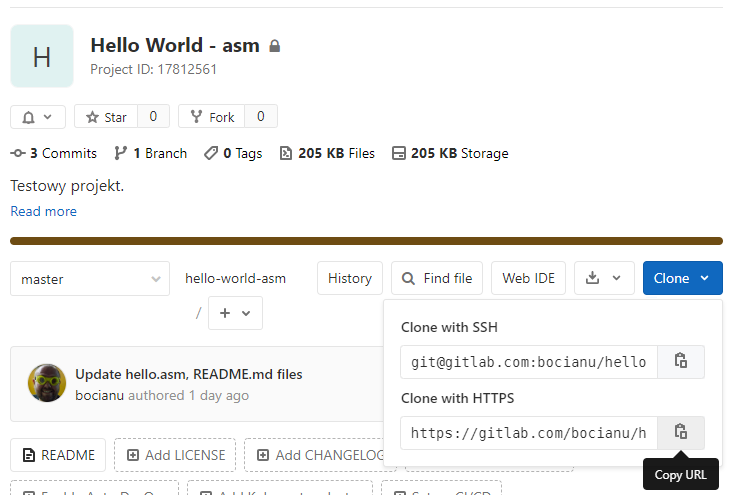
Klikamy Clone -> Clone with HTTPS. Kopiujemy adres repozytorium. Przechodzimy do linii poleceń w nowym katalogu:
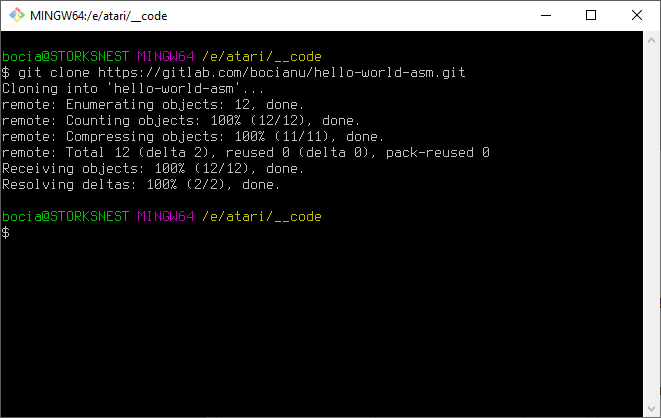
I tylko tyle. I aż tyle. Od teraz w katalogu hello-world-asm masz lokalną kopię repozytorium i najnowszą wersję mastera, którą możesz sobie do woli edytować. Wystarczy powtarzać poznany wcześniej workflow:
- robimy zmiany w plikach
- po każdej większej zmianie -> git commit -a -m 'opis zmian'
- jak nie kończymy jeszcze pracy to wróć do 1.
- kończymy pracę na dziś -> git push
Oczywiście po powrocie na komputer stacjonarny pierwsze co robimy to: git pull i mamy najnowszą wersje do dalszej edycji.
Może się zdarzyć sytuacja w której zapomnimy zrobić sobie git pull i rozpoczniemy edycję na starszej wersji kodu. Zrobiliśmy kilka commitów i nagle przy próbie sunchronizacji przez git push dostajemy taki komunikat.
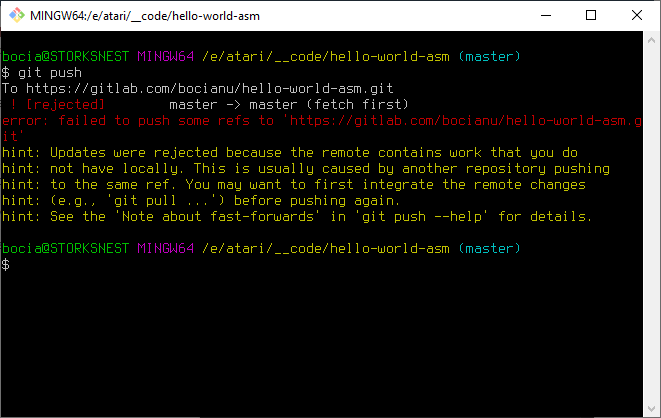
O Matko! Na czerwono! Znaczy że jest bardzo źle. Ale nie wpadajmy na razie w panikę. Zgodnie z zaleceniem robimy spóźnione git pull aby spróbować automatycznie połączyć zmiany w obu repozytoriach:
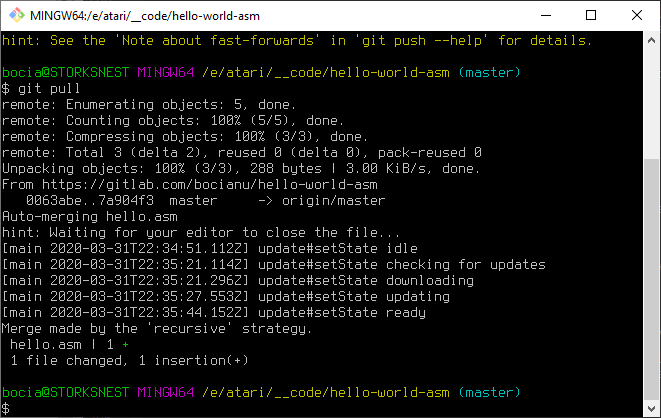
I jeżeli mamy szczęście to zobaczymy że udało się automatycznie połączyć (zmergować) nasze wcześniejszcze zmiany z obecnymi. Jedynym naszym problemem będzie wtedy to, że zostaniemy poproszeni o podanie opisu co ze sobą scalamy, podobnie jak przy commicie. Zwykle udaje się to bez problemu, o ile pracowaliśmy na różnych miejscach w kodzie. Jeżeli jednak zdarzy się tak, że w obu miejscach edytowaliśmy te same linie kodu, to dostajemy conflict i musimy sobie ręcznie połączyć zmiany w problematycznym pliku.
I tutaj muszę trochę wyhamować, bo samego automatycznego mergowania jest kilka strategii i masa narzędzi i sposobów jak to robić dobrze, a znów - nie ma być to tematem tego poradnika. Starajcie się unikac konfliktów, bo będziecie musieli się douczać jak je rozwiązywać samemu. Na przykład tutaj.
Załóżmy, że git pull się powiódł, albo że rozwiązaliśmy już wszystkie konflikty, to powtarzamy jeszcze raz wcześniej nieudane polecenie git push, aby połączone lokalnie pliki przesłać do zdalnego repozytorium. I FAJRANT! Z pewnością już nigdy więcej nie zapomnimy zrobić git pull przed rozpoczęciem pracy, prawda?
W SUMIE TO GIT
No i na ten moment, jesteście gotowi na publikowanie swoich projektów i korzystanie z wielu dobrodziejstw Gita i GitLaba. Serdecznie Was do tego zachęcam. Namawiam tez, na uwalnianie kodu, czyli do używania repozytoriów publicznych. Nie wstydźcie się swojej pracy, o ile nie będą to projekty komercyjne! Wasz kod będzie nieocenioną pomocą dla osób które sie dopiero uczą. A być może ktoś zainteresuje się Twoim projektem na tyle, że sam spróbuje coś w nim poprawić lub zmienić?
Obiecywałem na początku tego poradnika, że skonfigurujemy GitLaba tak, żeby jeszcze kompilował nasz kod po każdej zmianie. Pamietam! Ale to już dopiero w następnej części tego poradnika. Gratuluję, jeżeli dotarłeś do tego miejsca.