

ATARI vs Gitlab - część 3
Data publikacji:16.04.2020
CO TO JEST CI / CD?
Jak obiecywałem kilkukrotnie w poprzednich dwóch częściach, skonfigurujemy GitLaba tak, żeby nasz kod był automatycznie kompilowany po stronie serwera. Oczywiście, kompilować i testować lokalnie jest szybciej i GitLab nigdy nie zastąpi nam dobrze skonfigurowanego środowiska lokalnego. Ani pod względem wygody, ani szybkości. Tym niemniej z kilku powodów nie jest to głupi pomysł, aby mieć awaryjne środowisko na specjalne okazje. Poza tym (jak dla mnie) wystarczającym powodem, aby kompilować kod zdalnie, jest tylko to że można :D Skoro się da, to dlaczego nie?
GitLab udostępnia dwa specyficzne mechanizmy umożliwiające nam wykonywanie różnych ciekawych działań na naszym kodzie już po jego przesłaniu na serwer. Mechanizmy te, są zazwyczaj używane do automatyzacji testów, automatycznego budowania aplikacji, automatycznej dystrybucji oprogramowania i paru innych rzeczy.
Ich magiczne nazwy to CI i CD, które rozwijamy na Continuous Integration oraz Continuous Delivery.
Najpierw parę słów o Continuous Integration. Tłumaczymy sobie to jako "ciągła integracja" i jest to mechanizm, który w swoim założeniu i zgodnie z nazwą służy do "łączenia" ze sobą pewnych elementów i testowania czy prawidłowo współdziałają. Mogą to być poszczególne części naszej aplikacji i testowanie czy te komponenty ze sobą prawidłowo współpracują. Mogą to być testy współdziałania naszej aplikacji z zewnętrznymi usługami. Mogą to też być testy samej aplikacji... opcji jest bardzo dużo. Wszystko zależy od naszej kreatywności, pracowitości i umiejętności.
O ile automatyzacja testów aplikacji posiadających własny interfejs komunikacyjny i/lub jakieś jasno zdefiniowane API jest relatywnie łatwa, o tyle w naszym przypadku, gdy będziemy pisali program nie działający bezpośrednio na platformie GitLab tylko w emulatorze, przeprowadzenie testów jest bardzo utrudnione. Ale nie całkiem niemożliwe! Tak czy owak, temat testów tym razem pominiemy i zajmiemy się tą drugą częścią integracji: budowaniem binarnej dystrybucji naszej aplikacji z kodu źródłowego - czyli kompilowaniem - chociaż w naszym przypadku będzie to w zasadzie assemblacja, bo mamy program w assemblerze, ale wiecie o co mi chodzi.
Zanim przejdziemy wreszcie do konkretów, to jeszcze parę słów o Continuous Delivery. Tutaj polskie tłumaczenie jest już nieco mniej zgrabne, bo brzmi: "ciągłe dostarczanie", ale przymknijmy oko na tę dziwną nazwę. Ciągłe dostarczanie to proces, który zwykle rozpoczyna się tuż po zakończeniu CI. Czyli w momencie gdy mamy już zbudowaną (i przetestowaną) właściwą i sprawną wersję naszego programu nadchodzi czas aby "dostarczyć" ją w miejsce docelowe. Czyli na przykład na serwer produkcyjny, serwer dystrybucyjny, lub do jakiegoś repozytorium oprogramowania... tutaj również mnogość opcji jest ograniczona jedynie naszą kreatywnością i umiejętnościami.
My w naszych przykładach wykorzystamy sobie ten mechanizm, aby naszą najnowszą, skompilowaną wersję programu udostępnić do pobrania na stronie WWW. Czy to dla nas samych, czy to dla użytkowników końcowych. To już zależy tylko od nas. No to dosyć tych przydługich wstępów i do dzieła!
BUDUJEMY NOWY OBX
Oczywiście samo budowanie naszej aplikacji będzie przebiegało na serwerze GitLaba, to nie brałbym tych słów zupełnie dosłownie. Wątpię, żeby GitLab czy jakikolwiek inny serwis udostępnił nam swoje zasoby wprost i powiedział: Masz tutaj linię poleceń naszego serwerka i kompiluj se co tam potrzebujesz. Nie tak to wygląda w praktyce, ale dosyć podobnie, tyle że z zastosowaniem wirtualizacji. GitLab udostępnia nam "workera" który uruchamia maszynę wirtualną istniejącą tylko na czas działania CI/CD, a po zakończeniu pracy jest ona niszczona. Może to być maszyna z linuxem, z windowsem, albo nawet jakiś przygotowany własnoręcznie przez nas gotowy obraz środowiska. To sobie konfigurujemy na starcie naszego procesu.
Do konfiguracji środowiska CI/CD wykorzystujemy w GitLabie plik o nazwie .gitlab-ci.yml w pliku głównym naszego projektu. Możemy go dodać ręcznie, możemy wykorzystać GitLaba aby utworzył nam automatycznie taki plik korzystając z wbudowanych szablonów. Oczywiście nie mamy co liczyć na gotowy szablon do budowania aplikacji na Atari, więc musimy założyć go sobie sami. Można to zrobić na wiele sposobów, ale my wykorzystamy sobie do tego GitLaba.
Na stronie głównej projektu klikamy plusik i wybieramy New File:
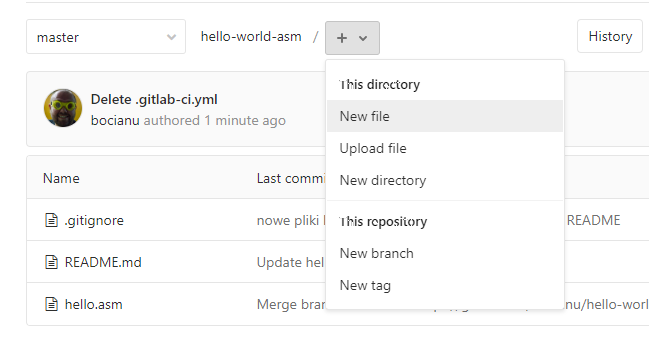
Możemy wpisać nazwę .gitlab-ci.yml z paluszka, albo wybrać gotowy "template".
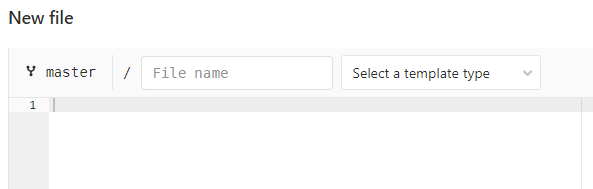
No dobra, mamy nowy pusty plik i co tu teraz wpisać? Co to za dziwne rozszerzenie yml??
Pliki yml sa napisane w języku YAML. Brzmi to, jak coś nowego do nauczenia sie, ale nie jest tak źle. Jest to język do zapisu ustrukturyzowanych danych i mimo, że brzmi to groźnie, to wcale nie jest takie trudne. W założeniu chodzi tylko o to, żeby dane były czytelne dla człowieka, a język był prosty w użyciu. I to ogólnie działa. W skrócie wygląda to tak, że każda dana to kolejna linia, a ich hierarchię ustalają wcięcia. Zaraz zrozumiesz o co chodzi.
Zaczniemy tym razem trochę od końca: wstawię gotowy plik yml i na przykładzie będę tłumaczył każdą sekcję.
Tak będzie łatwiej.
.gitlab-ci.yml
image: ubuntu
before_script:
# install all needed tools
- apt-get update -y
- apt-get install fp-compiler git -y
# download and compile MAD-Assembler
- git clone https://github.com/tebe6502/Mad-Assembler.git
- fpc -Mdelphi -v Mad-Assembler/mads.pas
# set permissions
- chmod +x Mad-Assembler/mads
build:
script:
# build atari binary
- Mad-Assembler/mads hello.asm
artifacts:
paths:
- hello.obx Jak widzicie nie jest tak strasznie z tym YAMLem. Wcięcia są w miare czytelne, Linie rozpoczynające się od znaku # są komentarzami. A teraz po kolei omówimy sobie poszczególne sekcje.
image: ubuntu - ta linia informuje jakiego obrazu maszyny wirtualnej użyjemy sobie do budowania naszej aplikacji. Ja wybrałem sobie linuksa w dystrybucji ubuntu, ale nic nie stoi na przeszkodzie, abyście wybrali sobie inna, o ile znacie ją na tyle dobrze, że potraficie na niej skompilować sobie program na Atari. Lista dostępnych obrazów jest ogromna. Możemy tam znaleźć przeróżnie bardziej i mnie popularne systemy i ich dystrybucje. Są obrazy już specjalnie skonfigurowanych maszyn do specjalnych zadań. Możemy też przygotowywać sobie swoje własne obrazy dockera i korzystać z nich. To już jest oczywiście poza zakresem tego poradnika. Wam na razie wystarczy wiedza, że możecie sobie dla swoich potrzeb wybrać dowolny obraz, który znajdziecie w repozytorium Docker Hub. O tym, czym jest sam docker i jak go używać do innych potrzeb niż nasza, też znajdziecie sporo materiałów na sieci. Kto lubi tematy wirtualizacji serdecznie polecam. To świetne narzędzie.
Po zdefiniowaniu naszego obrazu, nasz worker na początku procesu pobiera sobie żądany obraz i uruchamia go, przekazując nam kontrolę nad linią poleceń wybranego systemu i tutaj zaczyna się właściwa zabawa. Zatem lecimy dalej i trafiamy na sekcję before_script. W tym miejscu następuje lista poleceń, które wykonujemy na nowo uruchomionym systemie, aby przygotować go do pracy nad naszymi źródłami. W naszym pierwszym przykładzie będzie to zainstalowanie Gita i kompilatora Free Pascala, który będzie nam potrzebny do skompilowania Mad Assemblera, którym następnie skompilujemy sobie nasze źródło. Incepcja :)
Kolejne polecenia skryptu są oddzielone nowymi liniami zaczynającymi sie od myślnika, które ja pominę na potrzeby tłumaczenia o co tutaj chodzi:
apt-get update -yTo polecenie pobiera i/lub aktualizuje listy najnowszych pakietów oprogramowania dostępnych dla naszej dystrybucji ubuntu. Jest niezbędne, aby wykonać następne polecenie:
apt-get install fp-compiler git -yPowyższym poleceniem instalujemy gita, i kompilator Free Pascala. Parametr -y w tym i w poprzednim poleceniu oznacza, że program nie będzie o nic pytał, tylko uznaje Yes za odpowiedź domyślną. Więc możemy uznać, że w tym momencie mamy już zainstalowany i kompilator Free Pascala i Gita. Brakuje nam jeszcze assemblera, którym zbudujemy sobie plik binarny na nasze Atari.
git clone https://github.com/tebe6502/Mad-Assembler.gitTa komenda powinna wyglądać znajomo, o ile oczywiście czytałeś poprzednie części tego poradnika. Klonujemy repozytorium w którym TeBe trzyma najaktualniejszą wersję swojego znakomitego assemblera. Repozytorium zostanie pobrane do katalogu Mad-Assembler i tam je sobie skompilujemy następnym poleceniem, które przepisujemy wprost z instrukcji kompilacji na stronie autora.
fpc -Mdelphi -v Mad-Assembler/mads.pasPlik wykonywalny kompilatora zostanie utworzony w katalogu repozytorium. Jednak abyśmy mogli go wywołać, musimy mu nadać systemowe uprawnienie do wykonania\uruchomienia:
chmod +x Mad-Assembler/madsTutaj kończy się przygotowanie środowiska i przechodzimy do właściwej fazy integracji. Czyli tworzymy naszego pierwszego joba. Nazwiemy go sobie build, bo w końcu budujemy binarkę. Pierwsza sekcja bloku build to script, w której podobnie jak w poprzedniej sekcji, znajdują się polecenia wydawane do systemu z konsoli, a dokładnie to jedno polecenie:
Mad-Assembler/mads hello.asmUruchamiamy skompilowany przed chwilą assembler i assemblujemy nasz program.
No i w zasadzie tutaj moglibyśmy zakończyć nasz skrypt i wszystko poprawnie by się wykonało. Ale co z naszym plikiem binarnym hello.obx?? W momencie zakończenia wykonywania joba, maszyna wirtualna jest zwijana i kasowana. Więc wraz z nią zaginąłby nasz plik wynikowy. Ale na nasze szczęście możemy sobie zachowywać stworzone artefakty.
artifacts:
paths:
- hello.obxWystarczy wymienić w sekcji artifacts utworzone pliki lub/i całe foldery. A te zostaną "wyciągnięte" z wirtualnej maszyny i zachowane w postaci archiwum, do pobrania z GitLaba. Zaraz je znajdziemy, tylko najpierw zacommituj nasz nowo utworzony plik .gitlab-ci.yml
Od razu pojawia nam się tajemnicza ikonka, informująca nas, że "Pipeline is running"
No to zaglądnijmy do tego "rurociągu". Z menu po lewej klikamy CI/CD -> Pipelines

Jeżeli zdążyliśmy kliknąć w miarę szybko, to zobaczymy, że nasz rurociąg pracuje. A jak się spóźniliśmy, to zobaczymy widok z zakończonym zadaniem. Ikona po prawej stronie pozwoli nam pobrać nasz artefakt, czyli gotową binarkę!

No i pięknie! GitLab zassemblował nasz plik. Zajęło mu to jak widać 52 sekundy. Czyli: aby wyczerpać miesięczny darmowy limit 2000 minut działania workerów, musielibyśmy kompilować nasz projekt około 76 razy dziennie. To dużo. Ale trzeba też pamiętać, że bardziej skomplikowane konfiguracje, testy i inne działa potrafią tworzyć o wiele dłuższe procesy. Czyli rurociagi.
Klikając zielonego "checkboxa" w kolumnie stages, możemy podejrzeć jak przebiegał cały proces budowania naszego programu:
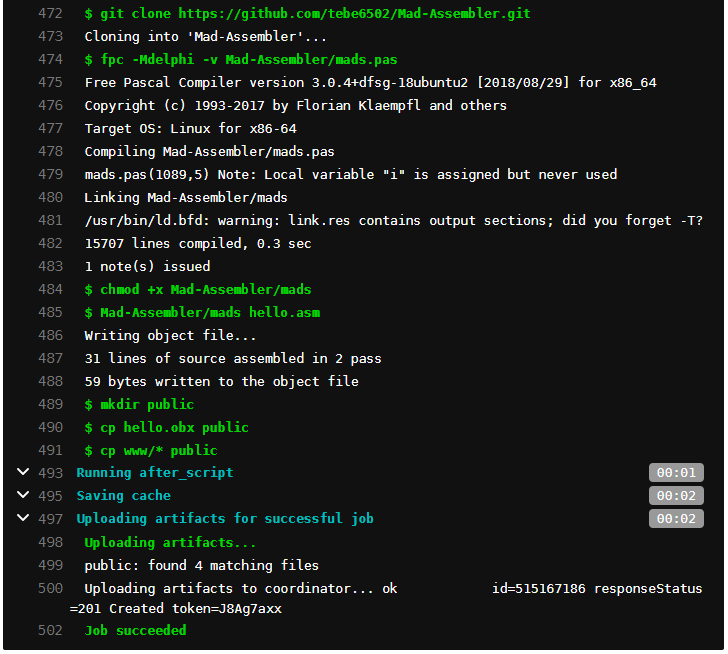
To oczywiście tylko fragment naszego loga. W przypadku kiedy popełnimy jakiś błąd w konfiguracji i nasz proces się posypie, jest miejsce w którym najczęściej sprawdzamy dlaczego. I polecam tutaj zaglądać po każdej większej zmianie konfiguracji naszego CI, aby sprawdzić, czy wszystko poszło po naszej myśli.
To teraz chwila teorii. Co to jest ten pipeline i jak sie ma do skryptu który pisaliśmy w YAMLu?
RUROCIĄGI i ich JOBY
Pamiętacie jak przy omawianiu pliku .gitlab-ci.yml wspominałem, że tworzymy pierwszego joba o nazwie build? Był to pierwszy i jak na razie jedyny job w naszym rurociągu. Ale nic nie stoi na przeszkodzie, aby robić tych jobów więcej. I zwykle w dużych projektach tak jest, że są osobne joby dla różnego rodzaju testów, osobny job do budowania aplikacji, osobny do publikowania na platformę docelową... I wtedy te joby "odpalane" są w ramach jednego rurociągu. I każda z nich jest uruchamiana w osobnej instancji wirtualnego środowiska. Daje nam to możliwości uruchamiania tych jobów współbieżnie, lub po kolei, jak tylko sobie zażyczymy. Ciekawskich odsyłam po raz kolejny do instrukcji w internecie, bo to wykracza poza mój założony zakres tego dokumentu.
Ale spróbujemy sobie zrobić jeszcze jednego joba, co?
Bo nie oszukujmy się, ale pobieranie naszego pliku wynikowego dla Atari z listy jobów nie jest specjalnie eleganckie. To może spróbujemy sobie dodać joba, który gdzieś nasz utworzony plik opublikuje? Tylko gdzie?
A co gdybyśmy mieli swój serwer, na który chcemy załadować ten plik przez ftp? Ostrzegam, że nie jest to wcale dobry pomysł. Głównym powodem jest to, że musielibyśmy się jakoś na ten serwer zalogować, czyli zapisać hasło w konfiguracji gitlab-ci. Tego nie róbmy.
No to co nam pozostaje w takiej sytuacji? Możemy skorzystać z darmowych hostingów plików pokroju file.io lub transfer.sh, na które to serwisy pliki wrzucimy jednym poleceniem z linii komend. Ale to też nie jest jakieś specjalnie wygodne i uniwersalne rozwiązanie. Ale i tutaj odpowiedzią może być mechanizm dostarczony przez GitLaba zwany Pages.
Jest to prosty mechanizm umożliwiający wyświetlenie statycznej strony HTML, połączonej z naszym kontem w serwisie GitLab. I dla każdego z projektów, może być to zupełnie osobny serwis. I jednocześnie jest to mechanizm bardzo prosty w użyciu. Jedyne co musicie zrobić, to utworzyć joba o nazwie pages. Wewnątrz tego joba zakładamy katalog public, do którego skopiujemy nasze pliki. I tyle.
Spróbujmy!
.gitlab-ci.yml
image: ubuntu
before_script:
# install all needed tools
- apt-get update -y
- apt-get install fp-compiler git -y
# download and compile MAD-Assembler
- git clone https://github.com/tebe6502/Mad-Assembler.git
- fpc -Mdelphi -v Mad-Assembler/mads.pas
# set permissions
- chmod +x Mad-Assembler/mads
build:
stage: build
script:
# build atari binary
- Mad-Assembler/mads hello.asm
artifacts:
paths:
- hello.obx
pages:
stage: deploy
script:
- mkdir public
- cp hello.obx public
- echo "<html><body><a href=hello.obx>Hello World - obx</a></body></html>" > public/index.html
artifacts:
paths:
- publicNajpierw szybko omówimy nowe rzeczy, które doszły w konfiguracji CI, a potem zaglądniemy, co tam nam się zbudowało. Przede wszystkim doszedł nam blok pages. Pierwszy parametr stage: deploy oznacza w którym miejscu naszej rury uruchamiamy naszego joba. Generalnie mamy 3 dostępne etapy:
test -> build -> deploy
I są one uruchamiane w dokładnie takiej kolejności jak powyżej. Dlatego też dodałem analogiczny wpis w jobie build. Gdybym nie dał tych parametrów, oba joby zostałyby uruchomione równolegle i z poziomu pages, nie mielibyśmy dostępnych artefaktów wyprodukowanych w build. A teraz mamy pewność, ze job pages zostanie uruchomiony dopiero gdy build zakończy swoją pracę.
W jobie pages widzimy też znajomą sekcję script. Zawiera ona polecenie utworzenia katalogu public:
mkdir publickopujemy do tego katalogu artefakt z poprzedniego builda:
cp hello.obx publici tworzymy sobie prosty szkielet pliku HTML, zawierający tylko link do pobrania naszej binarki.
echo "<html><body><a href=hello.obx>Hello World - obx</a></body></html>" > public/index.htmlKolejne linie to znana już z poprzedniego joba sekcja artifacts, gdzie umieszczamy nasz "publiczny" katalog. Sprawdźmy teraz co nam się zbudowało w zakładce CI/CD -> Pipelines:

Widzimy że oba etapy się powiodły i mamy już dwa artefakty do pobrania! No i super. Widzimy też, że czas działania wydłużył się prawie dwukrotnie, co jest logiczne, skoro uruchomiliśmy dwa joby zamiast jednego. I to tego jeszcze za chwile wrócimy, ale teraz zadajmy sobie to najważniejsze pytanie:
GDZIE TA NASZA STRONA?
Kliknijmy Settings -> Pages. Naszym oczom ukaże się poniższy widok:
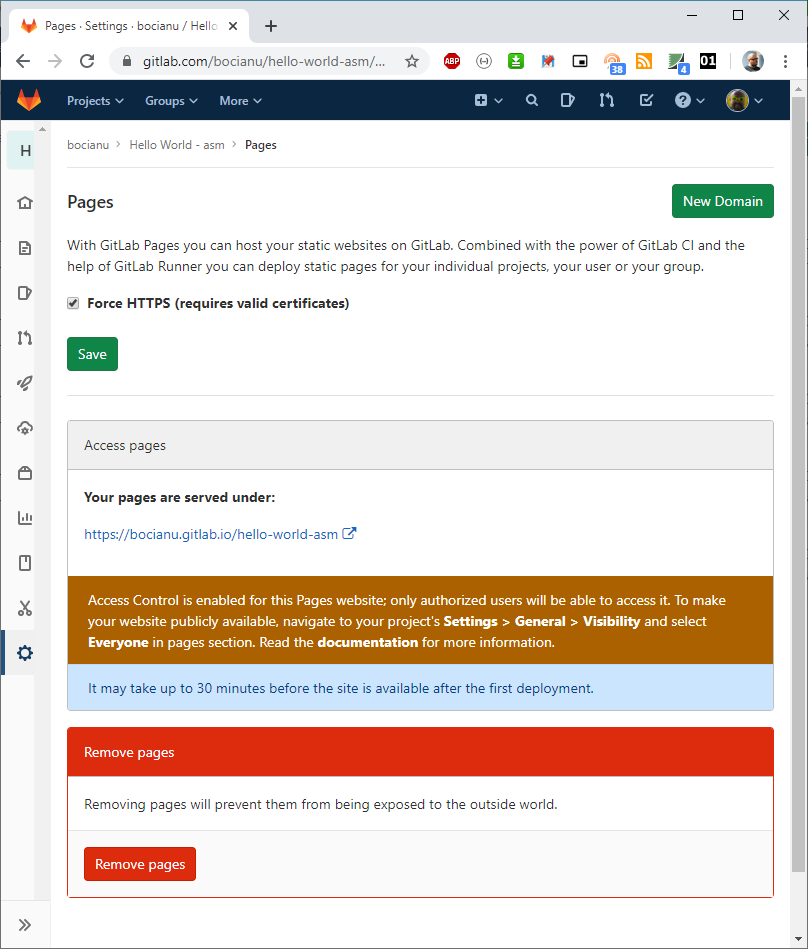
Widzimy adres naszej strony: https://bocianu.gitlab.io/hello-world-asm, który z pewnością w Twoim przypadku będzie nieco inny. Możesz się teraz niemiło zdziwić, ale prawdopodobnie zaraz po pierwszym utworzeniu Twoja nowa strona nie zadziała. Widzimy nawet adekwatną informację w niebieskim okienku.
It may take up to 30 minutes before the site is available after the first deployment.Zazwyczaj nie trwa to aż 30 minut, tylko krócej, ale pierwsze uruchomienie chwilę zajmuje. Ale jak strona już się pojawi, to każda kolejna aktualizacja pojawia się natychmiast. Wiec czekamy tylko pierwszy raz.
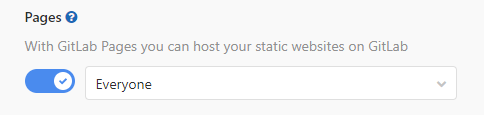
Tuż pod adresem widzimy informację, że nasza strona jest aktualnie "niewidzialna" dla innych użytkowników. To dlatego, że nasz projekt jest prywatny. W przypadku gdy utworzymy projekt jako publiczny, lub zmienimy na publiczny, strona staje się automatycznie widoczna. Ale możemy tez mieć prywatny projekt, a stronę dostępną dla wszystkich. Wystarczy wejść do Settings -> General -> Visibility i zmienić uprawnienia w sekcji Pages.
Zatem mamy już działającą stronę. Rzućmy na nią okiem:
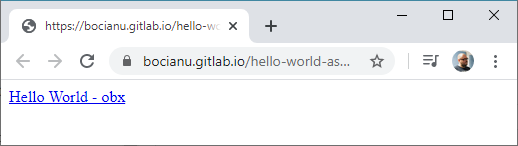
Klikamy - cyk - i mamy nasz plik.
Strona może nie jest piękna, ale działa i spełnia swoją rolę.
No i w zasadzie moglibyśmy na tym zakończyć. Ukłonić się, podziękować i iść w końcu spać,
ale jest jeszcze parę rzeczy, które można tutaj zrobić lepiej ;) Zacznijmy od tego, że odkąd dodaliśmy drugiego joba,
to nasze budowanie strony trwa prawie dwie minuty. A to zużywa nasze cenne darmowe minuty na GitLabowych workerach, oraz
nadwyręża naszą cierpliwość. Może nie potrzebujemy aż dwóch jobów? Może to zbytnia rozrzutność, że odpalamy osobnego joba
na budowanie, w którym tam naprawdę wykonujemy tylko jedno polecenie! Przecież w definicji joba pages również mamy
sekcję script. I tam tez możemy wykonać sobie kompilację naszego programu. Może będzie to mniej eleganckie, ale z pewnością
szybsze! No to sklejamy dwa joby i dodajemy nową sekcję, którą zaraz wytłumaczę:
.gitlab-ci.yml
image: ubuntu
before_script:
# install all needed tools
- apt-get update -y
- apt-get install fp-compiler git -y
# download and compile MAD-Assembler
- git clone https://github.com/tebe6502/Mad-Assembler.git
- fpc -Mdelphi -v Mad-Assembler/mads.pas
# set permissions
- chmod +x Mad-Assembler/mads
pages:
script:
# build atari binary
- Mad-Assembler/mads hello.asm
# deploy new page content
- mkdir public
- cp hello.obx public
- echo "<html><body><a href=hello.obx>Hello World - obx</a></body></html>" > public/index.html
artifacts:
paths:
- public
only:
- masterJak możecie zauważyć, pozbyłem się sekcji stage, bo skoro odpalamy tylko jednego joba, to kolejność nie ma znaczenia. Dodałem też nową sekcje: only z elementem "master". Oznacza to, że nasz job będzie uruchamiany tylko w przypadku, gdy jakieś zmiany pojawią się w gałęzi master. To dobra praktyka, bo po pierwsze, zazwyczaj w innych gałęziach testujemy/rozwijamy jakieś rzeczy, które niekoniecznie chcemy od razu publikować, a każdy commit zużywałby niepotrzebnie nasz darmowy czas. Innym sposobem, aby nie uruchamiać po commicie całego CI, (na przykład w przypadku gdy robimy jakieś zmiany, które nie zmienią naszej binarki) wystarczy do treści opisu commita dodać [ci skip]. Nawet w gałęzi master.
Tym sposobem odchudziliśmy nieco nasz plik konfiguracyjny i zaoszczędziliśmy nieco czasu, bo uruchamiamy tylko jednego joba. Ale rzućmy jeszcze raz okiem na naszą stronę. Nie wygląda to specjalnie pięknie, prawda? Może tutaj też chcielibyśmy dodać trochę więcej informacji? Wiec należałoby dodać trochę więcej treści do naszego pliku index.html. I tu pojawia się kolejne pytanie: może to niekoniecznie dobra praktyka, żeby generować treść pliku HTML wewnątrz pliku konfiguracyjnego? Każda zmiana wyglądu to zmiana konfiguracji. To niespecjalnie eleganckie rozwiązanie. A dlaczego by nie umieścić pliku index.html w naszym repozytorium i kopiować go stamtąd? Byłoby to dużo bardziej wygodne.
Żeby nie robić dodatkowego bałaganu w naszym repozytorium, utwórzmy sobie jakiś katalog w którym będziemy trzymali nasz szablon strony. Mogą tym być jakieś dodatkowe grafiki, arkusze styli... itp. Nazwijmy go sobie na przykład www i na początek stwórzmy sobie plik index.html i ostylujmy go plikiem css.
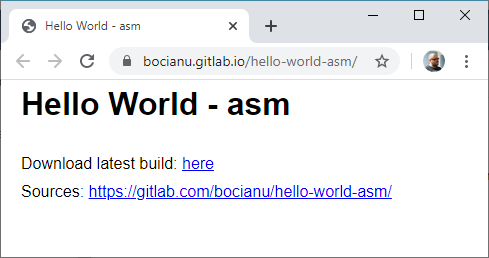
index.html
<html>
<head>
<title>Hello World - asm</title>
<link rel="stylesheet" type="text/css" href="styles.css">
</head>
<body>
<h1>Hello World - asm</h1>
Download latest build: <a href='hello.obx'>here</a><br>
Sources: <a href='https://gitlab.com/bocianu/hello-world-asm/'>https://gitlab.com/bocianu/hello-world-asm/</a><br>
</body>
</html>styles.css
* {margin:0;padding:0;border:0}
body {font-family: Arial, Helvetica, sans-serif; line-height:1.8em; margin: 10px 20px}
h1 {margin-bottom:1em}Jeżeli utworzyliśmy nasze nowe pliki przy pomocy przeglądarki i GitLaba, prawdopodobnie nasz katalog będzie wyglądał tak:
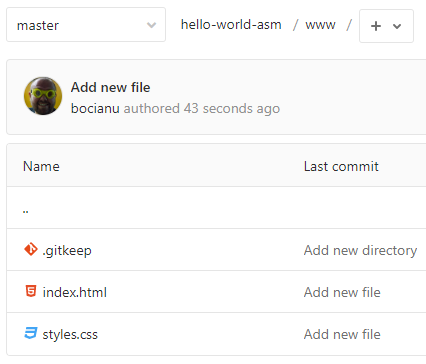
Skąd wziął się plik .gitkeep i po co? GitLab założył go sam. A po co? Bo inaczej nie byłby w stanie utworzyć pustego katalogu. Git ma taką cechę, ze nie jest w stanie commitować do repozytorium pustych katalogów, więc aby utworzyć jakikolwiek katalog GitLab tworzy w nim pusty plik .gitkeep. I to tyle. Po dodaniu jakiegokolwiek innego pliku do tego katalogu, możemy ten plik śmiało usunąć. Sytuacja taka nie będzie miała miejsca, jeżeli założymy sobie ten katalog w naszej lokalnej kopii repozytorium, bo wtedy prawdopodobnie zanim wykonamy jakikolwiek commit, najpierw utworzymy sobie jeszcze obydwa pliki, które siedzą w naszym katalogu. Więc nie będziemy commitować pustego folderu.
Dobra, koniec teorii. Teraz praktyka. Mamy już nasz szablon pliku strony i chcielibyśmy, żeby nasze CI potrafiło go wykorzystać. Więc po raz kolejny zmieniamy konfigurację, a w zasadzie to tylko jedną linię:
.gitlab-ci.yml
image: ubuntu
before_script:
# install all needed tools
- apt-get update -y
- apt-get install fp-compiler git -y
# download and compile MAD-Assembler
- git clone https://github.com/tebe6502/Mad-Assembler.git
- fpc -Mdelphi -v Mad-Assembler/mads.pas
# set permissions
- chmod +x Mad-Assembler/mads
pages:
script:
# build atari binary
- Mad-Assembler/mads hello.asm
# deploy new page content
- mkdir public
- cp hello.obx public
- cp www/* public
artifacts:
paths:
- public
only:
- masterNo teraz nasza strona wygląda już dużo lepiej i nie jesteśmy ograniczenie do malutkiego pliczku index.html.
Możemy teraz naszą stronę rozbudowywać, do naszego katalogu www możemy sobie pakować grafiki i inne elementy które będą współtworzyły naszą stronę. Jednak musimy pamiętać, że nie odpalimy tutaj żadnego PHP, ani innych skryptów wykonywanych po stronie serwera. To tylko statyczny serwis WWW.
A co gdybyśmy chcięli do naszej strony dodać jakieś dodatkowe informacje, takie jak np. data kompilacji, rozmiar pliku? Czy to możliwe bez skryptów po stronie serwera? Owszem! Ale o tym to już w kolejnej części.
Dowiemy się w niej także jak kompilować programy nie tylko w Assemblerze. Spróbujemy zmusić GitLabowe CI do zbudowania nam obrazu atarowskiej dyskietki. A na koniec dowiemy sie jak zbudować sobie uniwersalną konfigurację CI, którą będziemy mogli wykorzystywać w różnych projektach.
Na razie to tyle, dziękuję że dotrwałeś do tego miejsca i do zobaczenia w następnej części.
c.d.n.